“Of course, in the study of such complicated phenomena as occur in biology and sociology, the mathematical method cannot play the same role as, let us say, in physics. In all cases, but especially where the phenomena are most complicated, we must bear in mind, if we are not to lose our way in meaningless play with formulas, that the application of mathematics is significant only if the concrete phenomena have already been made the subject of a profound theory.“
A. D. Aleksandrov, A General View of Mathematics. In: A. D. Aleksandrov, A. N. Kolmogorov, M. A. Lavrent’ev, Mathematics: Its Content, Methods and Meaning. Moscow 1956 (trans. 1964)
I have recently added a new feature to the netvizz application: page like networks. This is basically a simple “like crawler” for like relationships between pages on Facebook. It starts with a seed page, gets all the pages liked by it, then gets their likes and so forth. Well, because the feature is new, I’m limiting crawl depth to two, in order to see how many resources are needed. In this post, I’ll quickly go over an example to show what one can do with this, but also to discuss a number of questions related to network analysis and visualization as such.
Network analysis and visualization (NAV) has made quite an entry into social science and humanities research circles over the last couple of years and the hype has contributed to the dominance of the network concept in new media studies and beyond. This dominance has been rightfully criticized and the pretty pictures of points and lines have received their fair share of disparaging commentary. While there are many questions and problems related to NAV, a lot of the criticism I have read or heard is superficial and lacks both understanding of the analytical gestures put forward by NAV and literacy of the diagrams one encounters so frequently now. Concerning the latter point, the main error is to consider the output of network visualization first and foremost as an image; with Barthes, I would suggest to look at them as denotative rather than connotative, as language or code more than image. This means that successful use of a network diagram requires reading skills and knowledge of the production apparatus. In their absence, well, every diagram looks likely the same.
To tease out something truly interesting from a graph – the mathematical representation of a network – a lot is needed and many, many mistakes can be made. But much like statistics, NAV is a powerful tool if handled with care. Let’s consider the following gephi diagram (data available as a .gdf file here, click for larger image):

This is the visualization of a network of 370 pages on Facebook with every node a page and every link an act of “liking”. Keeping with the topic of a recent data-sprint we had with our New Media and Digital Culture MA students about Anti-Islamism, I took the “Stop Islamization of the World” page as starting point and crawled two steps into the network. The result is a quite striking web of pages that clusters – at least according to gephi’s modularity algorithm – quite neatly into four groups. In purple, we find a group of pages (122 nodes) that are explicitly focused on countering Islam; in green – and very well connected to the first group – there is a “defence league” cluster (79 nodes), basically a network of strongly islamophobic street protest groups; in red, we see a group of sites associated with Israel (145 nodes); finally, in turquoise, a much smaller and eccentric group (24 nodes) that could be called “tattoo cluster” dedicated to getting ink done. Because pages do not necessarily reciprocate liking, this is a directed graph, i.e. every link has a source and a target. The curve of the links encodes this direction: a link that bends clockwise in relation to a node is an outgoing link, counter-clockwise is incoming. In this diagram – and in all that follow – node size is a simple count of inlinks.
How does one read something like this? What does it mean? At first glance, a like crawl starting with an islamophobic page results in a large number of pages related to Israel. But what kind of entanglement is this? I think that this question cannot be answered intelligently simply by looking at a single projection of the graph as a diagram. Besides a healthy distrust of the data (why this seed? why not others? how does crawl depth affect the result? are there privacy settings in place? etc.), any non-trivial network needs to be investigated from different angles to even begin understanding its structure. As I have tried to show elsewhere, different layout algorithms flatten the n-dimensional adjacency matrix into two-dimensional diagrams in quite different ways, each bringing particular aspects of the graph structure to the foreground. But there is much more to take into account. In the above diagram, we can easily spot nodes that are bigger than others, meaning that they receive more likes. (side node: it really helps to download all images and flip through them with a decent image viewer – all networks have exactly the same size and layout, only the color changes) Can we conclude that “United with Israel” and the “Isreali Defense Forces” (both 55 inlinks) are the most important actors in this network? And what would “important” then mean? Let’s start with Google’s definition and apply PageRank to our network using a heat scale (blue => yellow => red, click for larger image):

This is quite striking. We start with an Anti-Islam page and end up with the Isreali Defense Forces as the node with the most authority. Now, as I have tried to show recently, PageRank is a complicated beast and far from a simple measure of popularity. Rather, one can think about it as a complex flow of status along links that is highly dependent on topological positioning. Who links is at least as important as the number of links – and because status is passed along, the question of who does not link is crucial. Non-random networks are generally strongly hierarchical and PageRank exploits these asymmetries to the fullest. Let’s investigate further by looking at our network in aggregate form:
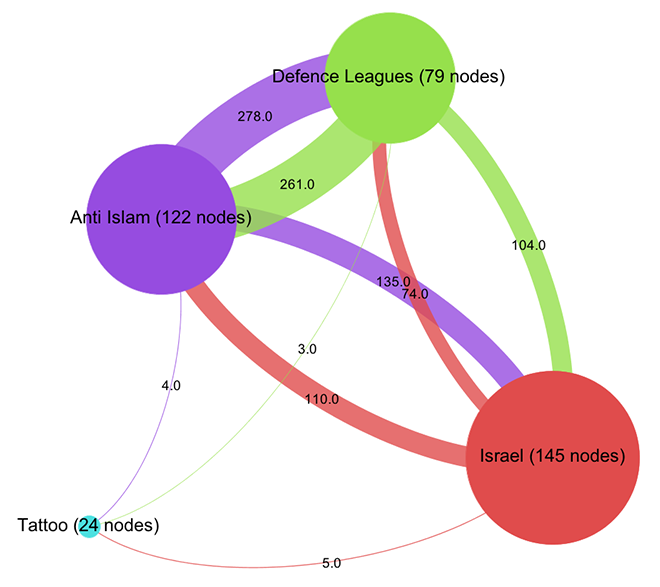
Already, a certain disequilibrium becomes visible here: while the Anti-Islam and Defence League clusters are liking back and forth in roughly equal manner, both like pages in the Israel cluster a lot more than they are liked back. But the disequilibrium is certainly not strong enough to simply diagnose a case of non-reciprocated affection. This would have been too easy. To further qualify the graph structure, we need to be able to say more about who links and who does not link. Let’s leave the force-based layout for a moment and look at the network in yet another way (click for larger image):
Here, I have not only arranged nodes on a line, grouped by clusters and ordered by inlink count, but I have also colored links according to their target. This means that we can very well see (on the hi-res image at least) into which cluster individual nodes are linking and even get an aggregate picture of relationships between groups. A nuanced account begins to emerge by looking at the linking practices of the top 10 pages: in the purple anti-islam cluster, page 1,2,4,6,7 and 9 link to the red israel cluster; in the green defence league cluster, 5 and 8 do so as well. But in the Israel cluster, only page 8 and 10 link to the former two. We can thus further qualify the disequilibrium mentioned above: in additional to a mere imbalance in numbers, we can observe a disequilibrium in status; high status nodes from the extremist clusters link to the Israel group, but the latter’s top pages do not like back. This explains why PageRank concentrates on the IDF page: it receives a lot of status, but does not feed it back into the network. If Facebook can stand in for the mapping of complex socio-political relationships – which it probably cannot – we could argue that the “official” Israel is clearly reluctant to associate with islamophobic extremism. But then, why is there a network in the first place? What holds it together?
Let’s start by looking at the most prolific likers in our network. The next diagram (click for larger image) shows the nodes with the highest outlink count:

Here, we see the most active likers, but we also notice that the page with the most likes (“We Stand With Israel – Siotw”) is quite small, which means that other pages do not like it very much. A better way to look at network cohesion in terms of structural positioning is thus to use a measure called betweenness centrality (click for larger image):

Betweenness centrality is often interpreted as close to the notion of bridging capital, i.e. the capacity of an actor to connect different groups. Because betweenness centrality is calculated by looking at the placement of nodes on the shortest paths in a network, it is not simply the heaviest linkers that are being put to the front here. However, some of the heavy linkers remain indeed important and if we take away “We Stand With Israel – Siotw”, a large number of the likes from the Israel cluster to the other two evaporate. The heavy linkers are indeed important for holding the network together.
But we also see the rise of a very interesting node, “Stand for Israel”. While it receives likes from apparently neutral pages such as “Visit Israel”, it is the top Israel cluster page to link into the Defence League cluster, to the “United States Defense League” page to be precise. While “Stand for Israel” announces on their page that “Violent, obscene, profane, hateful, or racist content will be deleted and offenders blocked from the page without notice” (and this indeed seems to be the case), they do like a page that is full of exactly that. That’s playing the role of a broker. In a sense, we can look at like patterns to produce actor descriptions.
What emerges through this still very superficial exploration – I made a point of not looking at the pages themselves as much as possible to focus on a pure NAV approach (which would be quite absurd in an actual research project) – is a set of rather complex relationships between pages that needs to be examined in different ways to even begin to make sense of. The diagrams, here, are not means to communicate findings, but artifacts that become truly salient only by combining, juxtaposing, and narrating them in combination. They are somehow less explanatory than in need of explanation. Let’s look at a final diagram to add yet another perspective (click for larger image):

Here, the heat scale encodes “like_count”, i.e. the number of times a page has been liked by Facebook users, not other pages. Suddenly, the picture flips completely. Albert Einstein and Tattoos lead the pack, but in the middle of the network, two nodes stand out, giving us further clues about how our clusters connect to larger political elements: “Tea Party Patriots” and “Being Conservative”.
Again, I would be very hesitant to make any claims based on the NAV of a set of Facebook pages and how they like each other, in particular in a context as sensitive as this one. Nonetheless, I hope that it becomes clear from this quick example that NAV provides means to investigate a network through multilayered and nuanced explorations of structural patterns that are simply not visible to the naked eye. And this is only a small subset of the many analytical gestures afforded by NAV. In my view, there certainly is an inflation of network diagrams and there are many limits to analyzing phenomena through formalization as points and lines. But much like the case of statistics, the often problematic use of formal techniques should not mean that we have to throw out the baby with the bathwater.
While I am still somewhat of a beginner in NAV, if there is one thing I have learned, it is that we should see network diagrams as specific projections or interpretations of the graph, as slices that interrogate data in particular ways, and that multiple such perspectives are needed to actually produce a picture.
The New York Times is not only a very good newspaper, it is also a really, really interesting archive that provides search access to all articles since 1851 via a pretty nice API. I’ve been meaning to play with it for some time, but things were extremely busy this year. But yesterday, I had some time in the evening and looked into the system a little bit and wrote a couple of scripts to try out some quick ideas.
While the API has all kinds of interesting things – in particular access to the Times’ controlled vocabulary – I am most interested in the article archive and the different possibilities to explore it. Understandably, the API does not provide the full text of articles; but it does search in the full text and for every found article it delivers quite a number of interesting things. Here is an example of what the returned data for a query (“guantanamo bay”) looks like:
While there are many things to go with, I found the manually attributed (and controlled) keywords to be particularly interesting. So I decided to explore and visualize how a particular subject evolves over time inside of this classificatory structure. Because the request rate for the search API is quite generous (10/s, 10K/day) I wrote a short PHP script (grab.php) that grabs this metadata for every article corresponding to a given search query. It simply downloads the data and stores it in a bunch of JSON files. A second script (analyze.php) then parses these files and creates a simple CSV file that can then be visualized with something like R (which I started working with some weeks ago, much easier than I thought, lots of fun).
With the help of the amazing ggplot2 library in R, using “guantanamo bay” as query, I quickly got a first result (click for larger image):
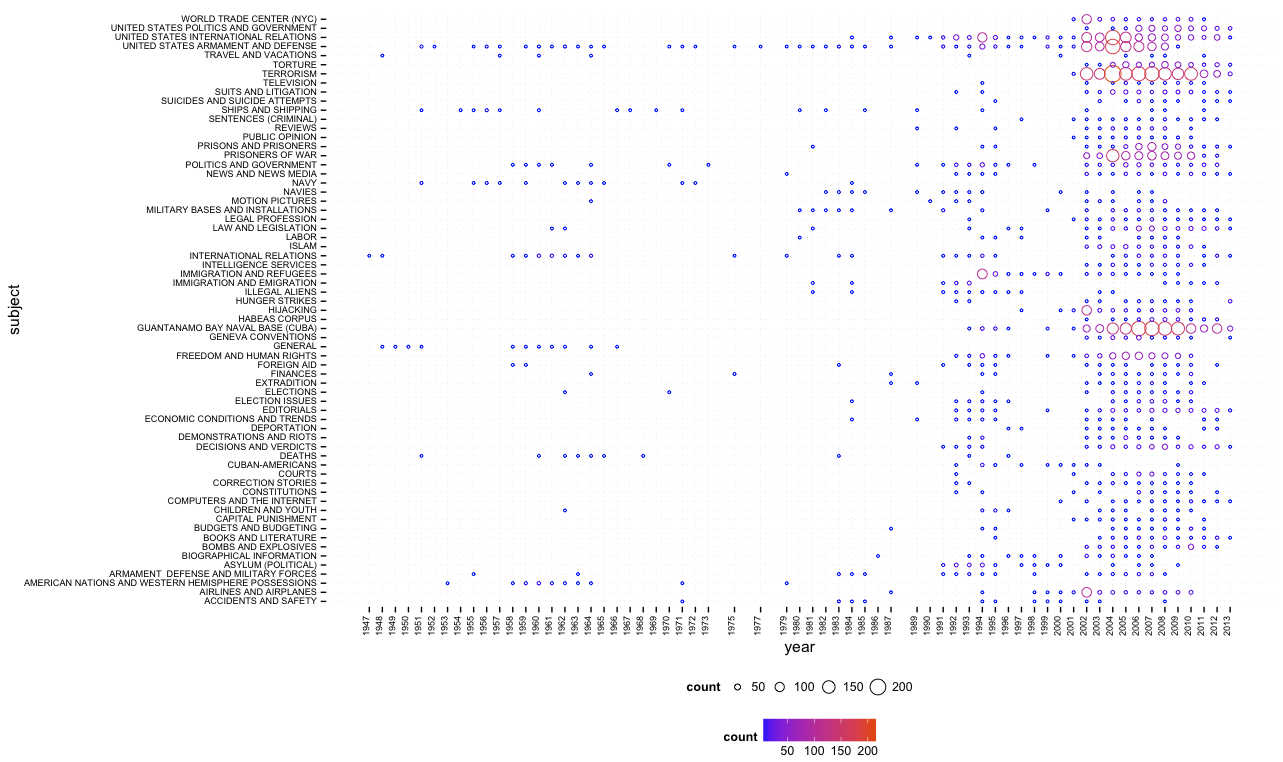
One can quite easily see that Guantanamo Bay was discussed in the 1990s in terms of immigration, asylum, and similar terms, while the current frame (terrorism, etc.) appears just after 9/11. While this script (bubbles.R) provides overview, a second one (bubbles_numbers.R) provides a combination of bubbles and numbers (click for larger image):

There is certainly much more interesting stuff to do with this data (e.g. different types of normalization, taking into account word count and page number, etc.) and I’ll hopefully come back to this in more detail in the future. In the meantime, all scripts can be found here.
Update June 2, 2013:
I’ve added a network export feature to the scripts on github. Generated network files are not limited to subject tags, but include people, organizations, locations, and creative works (e.g. books or movies). If two tags appear on the same article, a link is created and the more often they appear together, the stronger the connection. Here’s a quick visualization, made with gephi, of the most common people (red), organizations (green), and locations (blue) for the query “climate change” (click for larger image):

One of the reasons I started to develop the netvizz application, was to get better insights into how Facebook envisions exchange of data and functionality with third party developers. From the beginning, I was quite amazed how much data a third-party app could actually get from the platform – not only about the users that actually install an app, but also about their friends and the groups they are members of. I hope to provide a systematic account of what I’ve learned at some point in the future. But today, I want to discuss a particular element in some more detail, the “read_stream” permission.
To introduce the matter, a couple of points concerning the Facebook APIs as such: every application written by a third-party developer requires a logged in user and this user defines the “scope” of data access the running instance of the application can get – remember that applications are generally used by many users, so the data gleaned from individual scopes can be combined. Applications have to explicitly ask for permission to access certain items and Facebook provides extensive documentation on the permission system, the profile properties, and a set of extended permissions. Users are asked to grant these permissions when they first start an app. This is the permission dialogue for netvizz:

Netvizz currently asks for the following permissions: user_status, user_groups, friends_likes, user_likes, and read_stream. When installing, you cannot refuse individual elements that are not considered “extended permissions”, only decide to not use the app at all. The user_status is actually superfluous and will be removed in the next iteration. The user_groups permission is needed to access group data and both _likes permissions are used for netvizz’ like network functionality.
Now, working on a couple of new features over the last months, I started to get more interested in posts because they have probably become the closest thing to a “carrier of publicness” on the Facebook platform. I was quite amazed how easy it was to extract large numbers of users and (some) of their data from pages – both likes and comments users make on post on or by pages are in principle up for grabs. When doing some housekeeping recently, I noticed that some of the “engagement” metrics netvizz had provided for users’ friends in earlier versions were either broken or outdated and I decided to simply count the number of likes and posts friends make to replace the older metrics. I expected to only be able to read likes – through the friends_likes permission – and public posts. This was indeed true: in the beginning, all I got were public posts. Because I could get much more data through the Graph API Explorer, a developer sandbox that asks for all permissions by default (which can be changed, a great way to explore the permission structure), I discovered the read_stream permission.
The read_stream permission is presented by Facebook in the following way: “Provides access to all the posts in the user’s News Feed and enables your application to perform searches against the user’s News Feed.” It is a so-called “extended permission”, the developer doc noting that “Extended Permissions give access to more sensitive info and the ability to publish and delete data”. And, indeed, when asking for read_stream in netvizz, I suddenly got access to many more posts made by my friends, mostly going from “none” to “a lot”. From what I could gather after some random testing was that I basically got access to all of the activities from my friends that would show up in my newsfeed, without the “top stories” filter. Because many things have the status of “post”, I could get a rather detailed (and timestamped) account of what my friends are doing on the platform. You can check out your own “posts” feed by following this link into the Graph API Explorer. Because comments and likes by users who you are not friends with on posts by somebody you are friends with also show up in your news feed, the read_stream permission allows to capture their activity as well. Facebook seems to be aware of this: because read_stream is an extended permission it gets its own permission dialogue and can actually be skipped:

This is a good thing, but the wording seems a bit sparse: “Posts in your newsfeed” actually translates to “a minute account of your friends’ activities”. Granted, buried in the privacy settings is an option that allows us to modify more generally what information we share with the apps other people use, and these are the default settings:

It’s the “Activities, interests, things I like” option that allows the read_stream permission to work its magic. The people I am friends with on the platform are generally a rather privacy conscious bunch, but I could get the posts from most of them.
This is not a privacy scandal of any sort, measures are in place, but one can still make a couple of points:
- Apps as means for data capture are clearly not discussed enough. For serious data collection, however, going through the API is clearly the way to go and we need to pay more attention to this.
- Again and again: defaults matter. As seen above, the data available to apps used by friends is quite extensive with default settings.
- Again and again: language matters. The read_stream permission dialogue is certainly not explicit enough. Also: why is “app privacy” not in the privacy tab here?
- When we log into a third party site with our Facebook login, we are basically running an app. May be worth pondering what data we are shipping over.
Exploring APIs as important actors in the privacy debate and beyond is crucial. It’s often complicated work, though, and I hope that the developer community can help with that work a bit. It would be highly useful, I think.
Netvizz, a Facebook research app for extracting data from the dominant social networking service, has gained a new feature: page exploration. While the app has been able to get ego-networks and group networks from the start, this is the first time that data for pages can be extracted as well. The Social Network Importer for NodeXL already allows for extracting both co-engagement (users that comment or like the same post are connected) and bipartite networks (both posts and users are in the graph) from Facebook pages but requires you to use NodeXL and Microsoft Office on Windows.
The first implementation of page exploration on netvizz only provides bipartite network files only and yields less data on users, but adds information on the page posts themselves and outputs them both as a graph file and a simple tab-separated text file. For the moment, the app captures a user specified number of posts from the page and loads up to 1000 comments and 1000 likes. It also specifies the type of post in both of the files it generates. This is the (edgeless) network created from the last 100 posts of the New York Times Facebook page:

Users are gray, videos are blue, links are red, photos are yellow and status updates are green. Size is engagement. Because distance from the center indicates stronger engagement from non regular users, one can easily see that both photos and status updates are engaging a different audience than the links and videos.
Visualizing the data from the tsv file, we can explore these kind of relations further. Here, I used Mondrian‘s capacity to show highlights in one chart on all other open charts:


By selecting photos in the barchart, the scatterplot (x: likes, y: comments) shows that photos not only produce much higher engagement scores (the engagement value in both the tsv and gdf files combines numbers of likes, comments, shares, and likes for comments into a single metric) – the median for links is 453, but 1724 for photos – but that there is also a tendency for photos to provoke a comment/like ratio that trends toward the former. This is data from about 10 days of activity, so not suited to make any larger claims – interesting nonetheless.
As already mentioned here, the next step is to produce network files for multiple pages.
In my last post, I previewed a feature that I am currently building into netvizz: posts and users that comment and like them are thrown together into a bipartite graph. In this approach, it is easy to combine data from different pages, here from the 30 latest posts of the New York Times and the Wall Street Journal, plotting 27K users (bigger image behind the click):

The app will start spitting out more metrics in the next version, but it’s easy to see from the gephi graph that the NY Times (red) has a bit more users (grey) than the WSJ (blue). There is a bit of overlap in terms of (active) audience, but in general, there seem to be quite distinct populations of the short span the data covers. Interestingly, one post – talking about the space shuttle Endeavor – is a true outlier: it has succeeded in capturing a less “specific” audience.
As this method could be applied to a potentially infinite number of pages, this is really becoming quite problematic in terms of privacy. I have cut the labels for users, but they are in the data. I am unsure about this for the moment, but this feature may not make it in full into the next version.
Pages are part of Facebook’s project to suck up the Web. They are also full of data. In the next version of netvizz I will add a feature that allows to dig into that data a little bit. Here is a preview:

This network (visualized with gephi) shows interactions on the Facebook page of the Guardian. I extracted all the likes and comments for the last 80 posts. On the whole, there are 9.500 users liking and commenting away. Each dark and labeled node is a post while all the others are users. A heat scale (blue => yellow => red) shows how often a user interacts with the page; size shows how often a node was liked or commented on (for pages) or liked and commented (for users).
One can see a a core of regulars in the middle of the graph, but the main engagement comes from a large majority of users that have only interacted with a single posts. These users drag the big subjects out to the margins in this specific spatialization. Engagement, here, comes from a fleeting audience rather than a more stable group or community.
There is still some testing to do, but I hope to get this feature ready soon for general use.
The second issue of computational culture is out and I am really looking forward to plunging into it once my teaching schedule leaves me a little bit more time. I am very happy that my paper made it in. As I am currently preparing a lecture on visual analysis for a class, I’ve been using the text for a bit of fun.
James A. Danowski‘s co-word tool wordij is unfortunately no longer online (why?), but it’s a really interesting and powerful piece of software and I used it here to create an alternative view of the paper (click for bigger image) with the help of gephi:

Many Eyes is still has a few tricks up its sleeve and this word tree visualization is really quite a strong tool for exploring the use and context of select words in a text:
These really work quite well on this particular paper, but I hope to spend more time with text analysis over the next months – working on historical papers from computer and information science – to see how well these and other tools hold up in a truly exploratory context.
Before moving back into media studies, I taught programming at various levels for quite a number of years. One of the things that always struck me, in particular at the beginner’s level, is how little my attempts to find different metaphors, explanations, ways of approaching the subject and practical exercises changed about a basic observation that would repeat itself over the years: some people get it, some don’t. Some students seem like they are born to program, while others cannot – even after long hours of training and no lack of trying – write even the simplest piece of functional and useful code.
Arstechnica has posted a really interesting piece relaying a Q&A on Stack Exchange on this exact topic: “can everyone be a programmer”? Amongst the different resources cited is a link to a paper from 2006 by Saeed Dehnadi and Richard Bornat from the School of Computing at Middlesex University that basically confirms the “double bump” so many programming teachers observe year after year (a lively discussion of the paper is here). What really struck me about the paper was not so much the empirical outcome though, neither the fact that a relatively simple test seems to yield robust results in predicting programming aptitude, but rather a passage that speculates on the reasons for the findings:
It has taken us some time to dare to believe in our own results. It now seems to us, although we are aware that at this point we do not have sufficient data, and so it must remain a speculation, that what distinguishes the three groups in the first test is their different attitudes to meaninglessness.
Formal logical proofs, and therefore programs – formal logical proofs that particular computations are possible, expressed in a formal system called a programming language – are utterly meaningless. To write a computer program you have to come to terms with this, to accept that whatever you might want the program to mean, the machine will blindly follow its meaningless rules and come to some meaningless conclusion. In the test the consistent group showed a pre-acceptance of this fact: they are capable of seeing mathematical calculation problems in terms of rules, and can follow those rules wheresoever they may lead. The inconsistent group, on the other hand, looks for meaning where it is not. The blank group knows that it is looking at meaninglessness, and refuses to deal with it.
While a single explanatory strategy like this is certainly not enough, I must admit that I have rarely read something about teaching programming that comes as close to my own experience and intuition. It was always my impression – and I have discussed this in great length with some of my peers – that programming requires a leap of faith, an acceptance of something that contradicts many of the things we have learned from our everyday experience. When programming, we are using words to build a machine and because the “meaning” of software is expressed through the medium of functionality, the words we write are simply not expressive in the same way as human language.
Over these last years, there has been a debate in software studies and related fields about the linguistic vs. functional dimension of “code”, and I have always found this debate to be strangely removed from the practice of programming itself (which may actually be a goal rather than an omission), perhaps simply because I have always seen the acceptance of the meaninglessness – in terms of semantics – of programming languages as a requirement to be a programmer. This does not mean that code does not have meaning as text but, to put it bluntly, if one cannot suspend that belief and look through the code directly into the functionality it produces, one cannot be a programmer. This is also the reason why I am so skeptical about the focus on code and the idea that scholars interested in software have to “learn how to write code”. Certainly, programming languages, development environments, etc. structure the practice – they open certain doors and close others, they orient and facilitate – but in the end, from the perspective of the programmer, the developer who actually builds a program the true expressiveness of software is behind the code; and when developers discuss the different advantages and disadvantages of various programming languages, they are measuring them in terms of how to get to that behind, how they allow us to pierce through their formalism, their meaninglessness to get to the level of expression we are actually speaking on: functionality.
This is the leap of faith that I have seen so many students not be able to commit to (for whatever reason, perhaps not the least my incapacity to present it in a way they can relate to): to accept the pure abstract performative formality of the words you are writing and see the machine behind the text. Because for those who program – and they are certainly not the only ones who have the right to speak about these matters – the challenge is to go through one kind of language (code) to get to another kind of language (function).
The example discussed in the paper – and used as a test – is telling:
int a = 10;
int b = 20;
a = b;
I do not know how many times I have tried to explain assignment. One of the tricks I came up with was the “arrow to the left” idea: a = 10 does not mean that a is equivalent to 10 but that the “=” should be a “<=” that puts “what is on the right” into “what is on the left”. In my experience – and the paper fully confirms that – not every student can get to a functional understanding of why “a” contains the value “20” at the end of this script. Actually, the “why” is completely secondary. “a = b” means that you are putting the value for b into a. You’re doing it. Really. Really? I don’t know. But if you want to write a program you need to accept that this is what’s happening here. You don’t have to believe in it; formalism is about the commitment to a method, not an ontology. Let go of the idea that words mean something; here, they do something.
Software is not “linguistic” because source code has meaning – it may very well, but to write a program you have to forget about that – but because functionality is itself a means of expression. Despite the many footnotes I should add here, it is the capacity to be able to express the meaningful through the meaningless that makes a programmer. We have to let go a little of the world as we know it, in order to find it again, but in a different way.
This implies a very specific epistemological and even psychological stance, a way of unveiling the world in a certain manner. The question why this manner is apparently not everybody’s cup of tea may be a fruitful way to better understand what it actually consists of.
I am sick this weekend and that’s a justification to stay in bed and play around with the computer a bit. Over these last weeks, I was thinking that it may be interesting to get back to the aging netvizz application and make some direly needed revisions and updates, especially concerning some of the quantitative measures concerning individual users’ activity. Maintenance work is not fun, however, so I decided to add a new feature instead: the bipartite like network.
The idea is pretty simple: instead of graphing friend relationships between users, the new output basically just throws users and likes (liked pages that is – external objects are not available through the API) into the same graph. If a user likes something a link is created. That’s also how Facebook’s opengraph architecture works on the inside. The result – done with gephi – is pretty interesting though (click for bigger image):

The small turquoise dots are users and the bigger red ones liked objects. I eliminated users that did not like anything (or have strong privacy settings), as well as all things liked by a single person only. The data field “likesize” in the output file indicates how often an object has been liked and makes it possible to size likes separately from users (the “type” field distinguishes the two). It is not surprising that, at least in my case, the network of friendship connections and the like network are quite similar. People from Austria do not like the same things as my French friends – although there is a cluster of international stuff in the middle: television shows, music, wikileaks, and so on; these things cannot be clearly attributed to a user group.
One can actually use the same output file for something quite different. The next image shows the same graph but with nodes sized for number of connections (degree). This basically shows the biggest “likers” (anonymized for the purpose of this post) in the network and still keeps the grouped by similar like patterns.
 The new feature is already live and can be tried out. If you want to do more than make pretty pictures, I highly recommend checking out the work by my colleagues Carolin Gerlitz and Anne Helmond on what they call the “like economy”.
The new feature is already live and can be tried out. If you want to do more than make pretty pictures, I highly recommend checking out the work by my colleagues Carolin Gerlitz and Anne Helmond on what they call the “like economy”.
And now back to bed.