Social media platforms have become really huge. They have very large numbers of users, who share very large numbers of messages, images, videos, and so forth. They have a whole lot of spare cash, either from advertising revenue or from IPOs. They have not only become an intrinsic part of interpersonal communication and of the way we inform ourselves, but much of what news organizations report nowadays seems to be about who tweets what to whom with what effect. The controversy around how Facebook editorializes the newsfeed and trending topics is only the latest indicator for the enormous imprint on the circulation of information and ideas the company now has. The European Commission has recently launched a public consultation on the role of platforms, in reaction to two reports by the German and French governments on the topic.
One of the key terms in all of this is “transparency”. Often this concerns moments of decision-making such as ranking, filtering, pricing, suggesting, and so forth. And often the debate focuses on the role of algorithms vs moments of human discretion (the opposition is problematic in many ways, but that’s another topic). Demands for transparency then focus on “opening the black box” and Facebook’s recently published guidelines fit into this framework. But there is another aspect to transparency that is less often evoked, which concerns the question “what is actually going on in these platforms?”. This goes beyond the question of algorithms to include the very communicational makeup of these systems (interfaces, functions, etc.) and, even more importantly, the concrete results of large masses of users actually integrating these technical elements into their practices. Transparency, in that sense, is not simply concerned with knowledge about the system’s design, but with the ways users and technical infrastructure form an integrated whole that produces specific outcomes in terms of circulation of information and ideas. One way to understand this integrated whole a little better is empirical research, whether it happens on the micro level in the form of ethnography, on the meso level around specific issues, or on the macro level in the form of large statistical aggregations. Empirical research is, ultimately, the only way to understand what the editorializing (which includes the full design of the service, not just filtering) of Facebook and other companies actually means in terms of outcomes or effects.
But empirical research on large online platforms is getting more and more difficult. Last year, Facebook removed a number of functions from their API, and research applications like Netvizz lost a part of their capacity to produce transparency by giving researchers the means to do (a certain kind of data-driven) empirical research. The latest case is Instagram. Already a year ago, the company announced that every application would have to go through a permission review to be allowed to continue. My own Instagram Hashtag Explorer (which I renamed to Visual Tagnet Explorer – VTE – to conform to the app guidelines which prohibit the use of the company name) has been relying on API data to help researchers understand how people use Instagram to produce visual and textual accounts of issues, events, places, companies, and so forth. After submitting the app for review, I today received notification that the application was denied. A detailed description of the tool and a screencast that attempted to connect the tool – in not totally absurd ways I think – to the “accepted use cases” were not good enough to yield any more commentary than this:
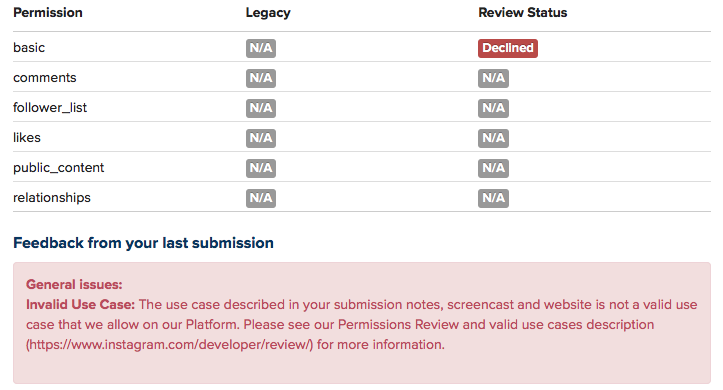
Now, we can lament about lost programming time (it wasn’t much fortunately) and research projects that will run into trouble, but the real problem, I think, connects to the question of transparency as I framed it above. Sure, a little script would never have solved the problem how to understand platform dynamics, but it was a little step on the ladder. There are certainly other means to do research and even data-driven research will be possible through scraping. But I wonder how far ethnographic studies, for example, are able to address questions concerning macro effects. And I wonder how sustainable and scalable scraping is. Sure, we can play the cat and mouse game with automatic bot detection and evolving interfaces, but is this going to produce the large window on these platforms we need to really understand them in terms of their effects on publicness? Maybe I’ll make some changes to VTE and submit it again, even though I have basically no feedback to go on. Maybe it will pass. But the larger problem will remain.
What is needed, I think, is something different. Yes, data retrieval, even by academic researchers, raises concerns about privacy. But privacy is not the only legitimate political aspiration, here. What, indeed, about publicness? What about the need to know about stuff in order to make democratic decisions? How to even begin to think about regulation if real outcomes are getting more and more difficult to assess? This is why I want to iterate an argument that I already tried to make during the EC’s public consultation: we need a legal framework to guarantee at least some access to API data, at least for some people. It is certainly nice that companies start research collaborations, but these fit of course into a sanitized view on their services. We therefore need, I think, something that is able to express the public’s legitimate interest to know “what’s going on” and access to API data is, in my view, a more promising avenue than the forms of purely technical or operational transparency that are often discussed. Fair use principles, for example concerning copyright, exist in academia because there is a belief that research that is not beholden to corporate interest performs a function in public life that is worth protecting. Can we imagine something similar with API data? A legally protected means to do research into these platforms? To find a compromise between privacy and publicness, we would have to find a way to distinguish between “disinterested” research and other applications. But technically, everything is in place. The APIs are there, even if they are closing down after their utility for growing the ecosystem has expired and selling data to analytics companies is becoming a revenue stream. The tools are in place and the researchers are starting to understand how to use them in useful ways. Compared to the daunting legal battles around antitrust measures, it’s almost banal to make this a reality.
Even if this idea proves to be a pipe dream, I think that we have to widen the debate around the values to take into account when criticizing the role of platforms in public life. Privacy is important, but public understanding of outcomes is as well.
2 Comments
Leave a Reply
Tech support questions will not be answered. Please refer to the FAQ of the tool.
Pingback: Potential scenarios for API research – The Social Platforms