Category Archives: epistemolgy
When it comes to digital methods, one of the basic conundrums one encounters is the ambivalence between platform and practice. To phrase it in basic terms: are outcomes genuine human practice or simply artifacts of the platform’s affordances? There are different ways to approach this problem conceptually and I would go as far as saying that it is a false problem, since I do not think that there is something like unmediated human practice in the first place. The fact remains, however, that we may want to focus on one or the other for various reasons. My own interest lie squarely in understanding the technical dimension and this post introduces an approach to studying the algorithms at work in social media platforms with the help of digital methods.
While a number of scholars have recently been engaged in attempts to reverse engineer relevant algorithms, the objects I am interested in are clearly too complex and dynamic to reproduce the decision mechanisms involved – which, in any case, are probably in constant movement due to machine learning components being part of the larger procedure. My goal is actually more basic and the approach I want to present is largely descriptive in the sense that it does little more than propose a way to talk about the outcomes of algorithmic work, in this case of ranking mechanisms. By “talk about”, I first mean graphically and quantitatively, but the goal, in fact, is quite qualitative. While I have real sympathies for the desire to describe artifacts considered to be the apogee of exactness in exact terms, I think that we need to explore other directions as well. In any case, we constantly examine and analyze phenomena in ways that do not require formal descriptions. We can study the NY Times’ editorial decisions – which involve a lot of ranking and appreciation of value – in ways that do not include building a formal decision model and still make interesting observations. Maybe it is time to see how methods for describing social phenomena can be used to describe formal mechanisms and not the other way round. What I have in mind does not go very far in this direction, but it embraces description as its methodology.
To make this idea more plastic, I take YouTube (YT) as my example and focus on YT’s search ranking. When looking for the keyword [syria], for example, YT returns an ordered list of videos. How can we talk about the produced rankings, here? One way would be to look into the factors YT itself communicates as relevant or turn to SEO blogs to gather attempts to identify the central variables. This is certainly interesting, but we could also just look at the results themselves. Using the YouTube Data Tools (YTDT), I have been collecting daily rankings for a number of keywords over the last months, [syria] being one of them. This file contains the data for five days. The rows are videos ordered by result rank and there is also a viewcount for each video. The file looks like this:
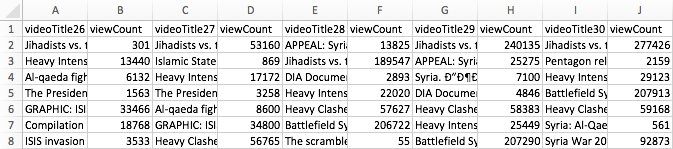
A very basic way to start making sense of these results is to visualize them. To help with this, I built a small tool, RankFlow, which is explicitly designed for analyzing rankings over time. Here is a screenshot of a visualization of the data (click for larger image):

Every column is a day of videos and each column is ordered by result rank. The height of each block encodes the viewcount variable as logarithm (to compress the vast differences in viewcount) while colors (from blue to red) indicate the unprocessed viewcount. The video with the highest viewcount actually only appears at rank 15 on the fifth day. What can we learn from such a basic visualization? First, absolute viewcount is obviously not the main ranking criterion. Second, rankings change quite a lot; between the second and the third day, for example, seven videos fall out of the top 15 and the video that comes in first on day three is again gone on day five. Third, there are a number of videos in the top ranks that have surprisingly low viewcounts. What I take from this case – and others I have looked at – is that YT probably uses a predictive ranking model that calculates something like a “chance to find an audience” metric (e.g. based on channels’ previous videos), places the video in the rankings, and – if it does not catch on – removes it again quite quickly (the top video on the first day is good example for a video that does catch on). This is in stark contrast to the “authoritative” rankings on Google Search that change much less frequently and tend towards something like a stable consensus. On YT, the ranking mechanism seems to “care” much more about quick turnover, newness, and serendipity. Looking at a simple RankFlow can give us a pretty good idea what is happening with a specific query and looking at a number of them can lead us to a more general assessment about output dynamics.
A second approach to describing ranking follows a direction that uses an algorithm to talk about another algorithm’s output. The problem with the above visualization is that it quickly gets very complicated to read and summarize when we start adding columns. But information scientists have been working on ways to produce quantitative measures to describe changes in rankings. On the bottom of the above visualization, you can see a number that tries to measure the changes between each two day pairs. There are many such measures available, but the one I found most intriguing came from a 2010 paper by William Webber, Alistair Moffat, and Justin Zobel. This was the one metric I found that would a) work with ranked lists where elements are not necessarily the same for each list (i.e. a video present on one day is no longer there on the next day), b) take into account changes in rank, not just presence or absence of an element, and c) attribute more value to changes at the top of the list than changes happening at the bottom. Rank-Biased Overlap (and its metrical form, Rank-Biased Distance) does just that. The RBD value between two days thus interprets changes in rank in a particular way and it condenses its interpretation into a single value. The higher the value, the more change. This is, of course, a reductionist gesture, but if we understand how the metric reduces, it can be extremely helpful to make sense of the “changiness” of rankings in a context where we have a lot of data. The algorithm (equation 32 in the paper, the “calc_rbo” function in my implementation) is not simple, but if you take some time to compare the visualization to the RBD values, you can get a basic feel for how it reacts to changes in rankings. This opens the door to more “macro” appreciations of changes in ranking and, interestingly, to comparison between platforms. A high average RBD value would indicate a tendency to fluctuate, a low value a preference for stability.
Both of these examples do not allow us to reverse engineer the actual algorithm(s) in question, but we need to get comfortable with the idea that this is not going to be an option in most cases anyways. Systematic description, however, allows us to still say something about the structure and dynamics of outputs and gives us an idea of the character or temperament of a ranking mechanism, for example. This post is just a starting point that I hope to turn into something more substantial in the future, but I hope it shows how relatively simple techniques can be employed to make potentially interesting findings.
In 1961, Information Pioneer Mortimer Taube (famous for popularizing mechanized coordinate indexing) wrote a book called Computers and Common Sense. The Myth of Thinking Machines. (Columbia University Press). Here is a quote that reminded me a lot of Philip Agre’s Computation and Human Experience:
About a year ago the author was privileged to sit one evening with a group of data processing experts who were attending an institute in Poughkeepsie. Conversation turned to learning-machines. Most of those present had no doubts that machines capable of learning would soon be built. When questions were posed concerning the nature of learning in men and machines and whether or not learning in one was similar or identical to learning in the other, a curious fact emerged. There was considerable agreement among those present concerning the nature of learning in machines, but wide disagreement concerning the nature of human learning. There was agreement that the term “learning,” when applied to human behavior, was vague and ill-defined in spite of the efforts of psychologists to evolve theories of learning. Out of all this a curious consensus emerged. Just because “learning” had no definite meaning when used to describe human behavior and did have a definite meaning when used to describe the activity of a machine, it seemed reasonable to accept the definition which applied to machines and to extend the same definition to cover human action. In other words, man-machine identity is achieved not by attributing human attributes to the machine, but by attributing mechanical limitations to man. (p.42)
“Of course, in the study of such complicated phenomena as occur in biology and sociology, the mathematical method cannot play the same role as, let us say, in physics. In all cases, but especially where the phenomena are most complicated, we must bear in mind, if we are not to lose our way in meaningless play with formulas, that the application of mathematics is significant only if the concrete phenomena have already been made the subject of a profound theory.“
A. D. Aleksandrov, A General View of Mathematics. In: A. D. Aleksandrov, A. N. Kolmogorov, M. A. Lavrent’ev, Mathematics: Its Content, Methods and Meaning. Moscow 1956 (trans. 1964)
I have recently added a new feature to the netvizz application: page like networks. This is basically a simple “like crawler” for like relationships between pages on Facebook. It starts with a seed page, gets all the pages liked by it, then gets their likes and so forth. Well, because the feature is new, I’m limiting crawl depth to two, in order to see how many resources are needed. In this post, I’ll quickly go over an example to show what one can do with this, but also to discuss a number of questions related to network analysis and visualization as such.
Network analysis and visualization (NAV) has made quite an entry into social science and humanities research circles over the last couple of years and the hype has contributed to the dominance of the network concept in new media studies and beyond. This dominance has been rightfully criticized and the pretty pictures of points and lines have received their fair share of disparaging commentary. While there are many questions and problems related to NAV, a lot of the criticism I have read or heard is superficial and lacks both understanding of the analytical gestures put forward by NAV and literacy of the diagrams one encounters so frequently now. Concerning the latter point, the main error is to consider the output of network visualization first and foremost as an image; with Barthes, I would suggest to look at them as denotative rather than connotative, as language or code more than image. This means that successful use of a network diagram requires reading skills and knowledge of the production apparatus. In their absence, well, every diagram looks likely the same.
To tease out something truly interesting from a graph – the mathematical representation of a network – a lot is needed and many, many mistakes can be made. But much like statistics, NAV is a powerful tool if handled with care. Let’s consider the following gephi diagram (data available as a .gdf file here, click for larger image):

This is the visualization of a network of 370 pages on Facebook with every node a page and every link an act of “liking”. Keeping with the topic of a recent data-sprint we had with our New Media and Digital Culture MA students about Anti-Islamism, I took the “Stop Islamization of the World” page as starting point and crawled two steps into the network. The result is a quite striking web of pages that clusters – at least according to gephi’s modularity algorithm – quite neatly into four groups. In purple, we find a group of pages (122 nodes) that are explicitly focused on countering Islam; in green – and very well connected to the first group – there is a “defence league” cluster (79 nodes), basically a network of strongly islamophobic street protest groups; in red, we see a group of sites associated with Israel (145 nodes); finally, in turquoise, a much smaller and eccentric group (24 nodes) that could be called “tattoo cluster” dedicated to getting ink done. Because pages do not necessarily reciprocate liking, this is a directed graph, i.e. every link has a source and a target. The curve of the links encodes this direction: a link that bends clockwise in relation to a node is an outgoing link, counter-clockwise is incoming. In this diagram – and in all that follow – node size is a simple count of inlinks.
How does one read something like this? What does it mean? At first glance, a like crawl starting with an islamophobic page results in a large number of pages related to Israel. But what kind of entanglement is this? I think that this question cannot be answered intelligently simply by looking at a single projection of the graph as a diagram. Besides a healthy distrust of the data (why this seed? why not others? how does crawl depth affect the result? are there privacy settings in place? etc.), any non-trivial network needs to be investigated from different angles to even begin understanding its structure. As I have tried to show elsewhere, different layout algorithms flatten the n-dimensional adjacency matrix into two-dimensional diagrams in quite different ways, each bringing particular aspects of the graph structure to the foreground. But there is much more to take into account. In the above diagram, we can easily spot nodes that are bigger than others, meaning that they receive more likes. (side node: it really helps to download all images and flip through them with a decent image viewer – all networks have exactly the same size and layout, only the color changes) Can we conclude that “United with Israel” and the “Isreali Defense Forces” (both 55 inlinks) are the most important actors in this network? And what would “important” then mean? Let’s start with Google’s definition and apply PageRank to our network using a heat scale (blue => yellow => red, click for larger image):

This is quite striking. We start with an Anti-Islam page and end up with the Isreali Defense Forces as the node with the most authority. Now, as I have tried to show recently, PageRank is a complicated beast and far from a simple measure of popularity. Rather, one can think about it as a complex flow of status along links that is highly dependent on topological positioning. Who links is at least as important as the number of links – and because status is passed along, the question of who does not link is crucial. Non-random networks are generally strongly hierarchical and PageRank exploits these asymmetries to the fullest. Let’s investigate further by looking at our network in aggregate form:
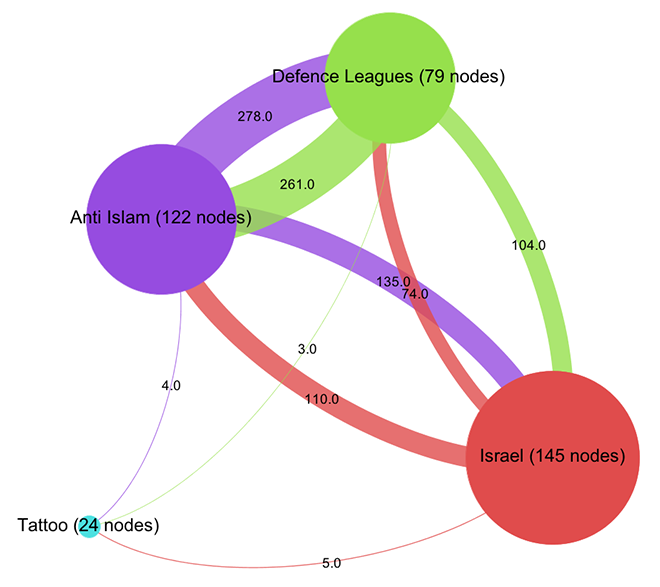
Already, a certain disequilibrium becomes visible here: while the Anti-Islam and Defence League clusters are liking back and forth in roughly equal manner, both like pages in the Israel cluster a lot more than they are liked back. But the disequilibrium is certainly not strong enough to simply diagnose a case of non-reciprocated affection. This would have been too easy. To further qualify the graph structure, we need to be able to say more about who links and who does not link. Let’s leave the force-based layout for a moment and look at the network in yet another way (click for larger image):
Here, I have not only arranged nodes on a line, grouped by clusters and ordered by inlink count, but I have also colored links according to their target. This means that we can very well see (on the hi-res image at least) into which cluster individual nodes are linking and even get an aggregate picture of relationships between groups. A nuanced account begins to emerge by looking at the linking practices of the top 10 pages: in the purple anti-islam cluster, page 1,2,4,6,7 and 9 link to the red israel cluster; in the green defence league cluster, 5 and 8 do so as well. But in the Israel cluster, only page 8 and 10 link to the former two. We can thus further qualify the disequilibrium mentioned above: in additional to a mere imbalance in numbers, we can observe a disequilibrium in status; high status nodes from the extremist clusters link to the Israel group, but the latter’s top pages do not like back. This explains why PageRank concentrates on the IDF page: it receives a lot of status, but does not feed it back into the network. If Facebook can stand in for the mapping of complex socio-political relationships – which it probably cannot – we could argue that the “official” Israel is clearly reluctant to associate with islamophobic extremism. But then, why is there a network in the first place? What holds it together?
Let’s start by looking at the most prolific likers in our network. The next diagram (click for larger image) shows the nodes with the highest outlink count:

Here, we see the most active likers, but we also notice that the page with the most likes (“We Stand With Israel – Siotw”) is quite small, which means that other pages do not like it very much. A better way to look at network cohesion in terms of structural positioning is thus to use a measure called betweenness centrality (click for larger image):

Betweenness centrality is often interpreted as close to the notion of bridging capital, i.e. the capacity of an actor to connect different groups. Because betweenness centrality is calculated by looking at the placement of nodes on the shortest paths in a network, it is not simply the heaviest linkers that are being put to the front here. However, some of the heavy linkers remain indeed important and if we take away “We Stand With Israel – Siotw”, a large number of the likes from the Israel cluster to the other two evaporate. The heavy linkers are indeed important for holding the network together.
But we also see the rise of a very interesting node, “Stand for Israel”. While it receives likes from apparently neutral pages such as “Visit Israel”, it is the top Israel cluster page to link into the Defence League cluster, to the “United States Defense League” page to be precise. While “Stand for Israel” announces on their page that “Violent, obscene, profane, hateful, or racist content will be deleted and offenders blocked from the page without notice” (and this indeed seems to be the case), they do like a page that is full of exactly that. That’s playing the role of a broker. In a sense, we can look at like patterns to produce actor descriptions.
What emerges through this still very superficial exploration – I made a point of not looking at the pages themselves as much as possible to focus on a pure NAV approach (which would be quite absurd in an actual research project) – is a set of rather complex relationships between pages that needs to be examined in different ways to even begin to make sense of. The diagrams, here, are not means to communicate findings, but artifacts that become truly salient only by combining, juxtaposing, and narrating them in combination. They are somehow less explanatory than in need of explanation. Let’s look at a final diagram to add yet another perspective (click for larger image):

Here, the heat scale encodes “like_count”, i.e. the number of times a page has been liked by Facebook users, not other pages. Suddenly, the picture flips completely. Albert Einstein and Tattoos lead the pack, but in the middle of the network, two nodes stand out, giving us further clues about how our clusters connect to larger political elements: “Tea Party Patriots” and “Being Conservative”.
Again, I would be very hesitant to make any claims based on the NAV of a set of Facebook pages and how they like each other, in particular in a context as sensitive as this one. Nonetheless, I hope that it becomes clear from this quick example that NAV provides means to investigate a network through multilayered and nuanced explorations of structural patterns that are simply not visible to the naked eye. And this is only a small subset of the many analytical gestures afforded by NAV. In my view, there certainly is an inflation of network diagrams and there are many limits to analyzing phenomena through formalization as points and lines. But much like the case of statistics, the often problematic use of formal techniques should not mean that we have to throw out the baby with the bathwater.
While I am still somewhat of a beginner in NAV, if there is one thing I have learned, it is that we should see network diagrams as specific projections or interpretations of the graph, as slices that interrogate data in particular ways, and that multiple such perspectives are needed to actually produce a picture.
Before moving back into media studies, I taught programming at various levels for quite a number of years. One of the things that always struck me, in particular at the beginner’s level, is how little my attempts to find different metaphors, explanations, ways of approaching the subject and practical exercises changed about a basic observation that would repeat itself over the years: some people get it, some don’t. Some students seem like they are born to program, while others cannot – even after long hours of training and no lack of trying – write even the simplest piece of functional and useful code.
Arstechnica has posted a really interesting piece relaying a Q&A on Stack Exchange on this exact topic: “can everyone be a programmer”? Amongst the different resources cited is a link to a paper from 2006 by Saeed Dehnadi and Richard Bornat from the School of Computing at Middlesex University that basically confirms the “double bump” so many programming teachers observe year after year (a lively discussion of the paper is here). What really struck me about the paper was not so much the empirical outcome though, neither the fact that a relatively simple test seems to yield robust results in predicting programming aptitude, but rather a passage that speculates on the reasons for the findings:
It has taken us some time to dare to believe in our own results. It now seems to us, although we are aware that at this point we do not have sufficient data, and so it must remain a speculation, that what distinguishes the three groups in the first test is their different attitudes to meaninglessness.
Formal logical proofs, and therefore programs – formal logical proofs that particular computations are possible, expressed in a formal system called a programming language – are utterly meaningless. To write a computer program you have to come to terms with this, to accept that whatever you might want the program to mean, the machine will blindly follow its meaningless rules and come to some meaningless conclusion. In the test the consistent group showed a pre-acceptance of this fact: they are capable of seeing mathematical calculation problems in terms of rules, and can follow those rules wheresoever they may lead. The inconsistent group, on the other hand, looks for meaning where it is not. The blank group knows that it is looking at meaninglessness, and refuses to deal with it.
While a single explanatory strategy like this is certainly not enough, I must admit that I have rarely read something about teaching programming that comes as close to my own experience and intuition. It was always my impression – and I have discussed this in great length with some of my peers – that programming requires a leap of faith, an acceptance of something that contradicts many of the things we have learned from our everyday experience. When programming, we are using words to build a machine and because the “meaning” of software is expressed through the medium of functionality, the words we write are simply not expressive in the same way as human language.
Over these last years, there has been a debate in software studies and related fields about the linguistic vs. functional dimension of “code”, and I have always found this debate to be strangely removed from the practice of programming itself (which may actually be a goal rather than an omission), perhaps simply because I have always seen the acceptance of the meaninglessness – in terms of semantics – of programming languages as a requirement to be a programmer. This does not mean that code does not have meaning as text but, to put it bluntly, if one cannot suspend that belief and look through the code directly into the functionality it produces, one cannot be a programmer. This is also the reason why I am so skeptical about the focus on code and the idea that scholars interested in software have to “learn how to write code”. Certainly, programming languages, development environments, etc. structure the practice – they open certain doors and close others, they orient and facilitate – but in the end, from the perspective of the programmer, the developer who actually builds a program the true expressiveness of software is behind the code; and when developers discuss the different advantages and disadvantages of various programming languages, they are measuring them in terms of how to get to that behind, how they allow us to pierce through their formalism, their meaninglessness to get to the level of expression we are actually speaking on: functionality.
This is the leap of faith that I have seen so many students not be able to commit to (for whatever reason, perhaps not the least my incapacity to present it in a way they can relate to): to accept the pure abstract performative formality of the words you are writing and see the machine behind the text. Because for those who program – and they are certainly not the only ones who have the right to speak about these matters – the challenge is to go through one kind of language (code) to get to another kind of language (function).
The example discussed in the paper – and used as a test – is telling:
int a = 10;
int b = 20;
a = b;
I do not know how many times I have tried to explain assignment. One of the tricks I came up with was the “arrow to the left” idea: a = 10 does not mean that a is equivalent to 10 but that the “=” should be a “<=” that puts “what is on the right” into “what is on the left”. In my experience – and the paper fully confirms that – not every student can get to a functional understanding of why “a” contains the value “20” at the end of this script. Actually, the “why” is completely secondary. “a = b” means that you are putting the value for b into a. You’re doing it. Really. Really? I don’t know. But if you want to write a program you need to accept that this is what’s happening here. You don’t have to believe in it; formalism is about the commitment to a method, not an ontology. Let go of the idea that words mean something; here, they do something.
Software is not “linguistic” because source code has meaning – it may very well, but to write a program you have to forget about that – but because functionality is itself a means of expression. Despite the many footnotes I should add here, it is the capacity to be able to express the meaningful through the meaningless that makes a programmer. We have to let go a little of the world as we know it, in order to find it again, but in a different way.
This implies a very specific epistemological and even psychological stance, a way of unveiling the world in a certain manner. The question why this manner is apparently not everybody’s cup of tea may be a fruitful way to better understand what it actually consists of.
Edit: slides
On Thursday, I will be giving a talk at the “The Lived Logics of Database Machinery” workshop, organized by computational culture, which will take place at the Wellcome Collection Conference Centre in London, from 10h to 17h30. I am very much looking forward to this, although I’ll be missing a couple of days from the currently ongoing DMI summer school. This is what I will be talking about:
ORDER BY column_name. The Relational Database as Pervasive Cultural Form
This contribution starts from the observation that, in a way similar to the computational equivalence of programming languages, the major types of database models (network, relational, object-oriented, etc.) and implementations are all able to store and manage a very large variety of data structures. This means that most data structures could be modeled, in one way or another, in almost any existing database system. So why have there been so many intense debates about how to conceive and build database systems? Just like with programming languages, the specific way a database system embeds an abstract concept in a set of concrete methods and mechanisms for specifying, accessing, and manipulating datasets is significant. Different database models and implementations imply different ways of “thinking” data organization, they vary in performance, robustness, and “logistics” (one of the reasons why Oracle’s product succeeded well in the enterprise sector in the 1980s, despite its lack of certain features, was the ability to make backups of a running database), and they provide different modes of interaction with both the data and the system.
The central vector of differentiation, however, is the question how users “see” the data: during the “database debates” of the 1970s and 1980s the idea of the database as a set of tables (relational model) was put in opposition to the vision of the database as a network of records (network model). The difference between the two concerned not only performance, flexibility, and complexity, but also the crucial question who the users of these systems would be in the first place. The supporters of the network model clearly saw the programmer as the target audience for database systems but the promoters of the much simpler relational model and its variants imagined “accountants, engineers, architects, and urban planners” (Chamberlin and Boyce 1974) to directly interact with data by means of a simple query language. While this vision has not played out, according to Michael Stonebreaker’s famous observation, SQL (the most popular, albeit impure implementation of Codd’s relational ideas) has indeed become “intergalactic data-speak” (most packages on the market provide SQL interfaces) and this standardization has strongly facilitated the penetration of database systems into all corners of society and contributed to a widespread “relational view” of data organization and manipulation, even if data modeling is still mostly in expert hands.
The goal of this contribution is to examine this “relational view” in terms of what Jack Goody called the “modes of thought” associated with writing, and in particular with the list form, which “encourages the ordering of the items, by number, by initial sound, by category, etc.” (Goody 1977). As with most modern technologies, the relational model implies a complex set of constraining and enabling elements. The basic structural unit, the “relation” (what most people would simply call a table) disciplines data modeling practices into logical consistency (tables only accept tuples/rows with the same attributes) while remaining “semantically impoverished” (Stonebreaker 1993). Heterogeneity is purged from the relational model on the level of modeling, especially if compared to navigational approaches (e.g. XPath or DOM), but the “set-at-a-time” retrieval concept, combined with a declarative query language, affords remarkable flexibility and expressiveness on the level of data selection. The relational view thus implies an “ontology” consisting of regular, uniform, and only loosely connected objects that can be ordered in a potentially unlimited number of ways at the time of retrieval (by means of the query language, i.e. without having to program explicit retrieval routines). In this sense, the relational model perfectly fits the qualities that Callon and Muniesa (2005) attribute to “powerful” calculative agency: handle a long list of diverse entities, keep the space of possible classifications and reclassifications largely open, multiply possible hierarchies and classifications. What database systems then do, is bridging the gap between these calculative capacities and other forms of agency by relating them to different forms of performativity (e.g., in SQL speak, to SELECT, TRIGGER, and VIEW).
While the relational model’s simplicity has led to many efforts to extend or replace it in certain application areas, its near universal uptake in business and government means that the logistics of knowledge and ordering implied by the relational ontology resonate through the technological layers and database schemas into the domains of management, governance, and everyday practices.
I will argue that the vision of the “programmer as navigator” trough a database (Bachman 1973) has, in fact, given way to a setting where database consultants, analysts, and modelers sit between software engineering on the one side and management on the other, (re)defining procedures and practices in terms of the relational model. Especially in business and government sectors, central forms of management and evaluation (reporting, different forms of data analysis, but also reasoning in terms of key performance indicators and, more generally, “evidence based” management) are directly related to the technological and cognitive standardization effects derived from the pervasiveness of relational databases. At the risk of overstretching my argument, I would like to propose that Thrift’s (2005) “knowing capitalism” indeed knows (largely) in terms of the relational model.
Yesterday, Google introduced a new feature, which represents a substantial extension to how their search engine presents information and marks a significant departure from some of the principles that have underpinned their conceptual and technological approach since 1998. The “knowledge graph” basically adds a layer to the search engine that is based on formal knowledge modelling rather than word statistics (relevance measures) and link analysis (authority measures). As the title of the post on Google’s search blog aptly points out, the new features work by searching “things not strings”, because what they call the knowledge graph is simply a – very large – ontology, a formal description of objects in the world. Unfortunately, the roll-out is progressive and I have not yet been able to access the new features, but the descriptions, pictures, and video paint a rather clear picture of what product manager Johanna Wright calls the move “from an information engine to a knowledge engine”. In terms of the DIKW model (Data-Information-Knowledge-Wisdom), the new feature proposes to move up a layer by adding a box of factual information on a recognized object (the examples Google uses are the Taj Mahal, Marie Curie, Matt Groening, etc.) next to the search results. From the presentation, we can gather that the 500 million objects already referenced will include a large variety of things, such as movies, events, organizations, ideas, and so on.

This is really a very significant extension to the current logic and although we’ll need more time to try things out and get a better understanding of what this actually means, there are a couple of things that we can already single out:
- On a feature level, the fact box brings Google closer to “knowledge engines” such as Wolfram Alpha and as we learn from the explanatory video, this explicitly includes semantic or computational queries, such as “how many women won the Nobel Prize?” type of questions.
- If we consider Wikipedia to be a similar “description layer”, the fact box can also be seen as a competitor to everybody’s favorite encyclopedia, which is a further step into the direction of bringing information directly to the surface of the results page instead of simply referring to a location. This means that users do not have to leave the Google garden to find a quick answer. It will be interesting to see whether this will actually show up in Wikipedia traffic stats.
- The introduction of an ontology layer is a significant departure from the largely statistical and graph theoretical methods favored by Google in the past. While features based on knowledge modelling have proliferated around the margins (e.g. in Google Maps and Local Search), the company is now bringing them to the center stage. From what I understand, the selection of “facts” to display will be largely driven by user statistics but the facts themselves come from places like Freebase, which Google bought in 2010. While large scale ontologies were prohibitive in the past, a combination of the availability of crowd-sourced databases (Wikipedia, etc.), the open data movement, better knowledge extraction mechanisms, and simply the resources to hire people to do manual repairs has apparently made them a viable option for a company of Google’s size.
- Competing with the dominant search engine has just become a lot harder (again). If users like the new feature, the threshold for market entry moves up because this is not a trivial technical gimmick that can be easily replicated.
- The knowledge graph will most certainly spread out into many other services (it’s already implemented in the new Google Docs research bar), further boosting the company’s economies of scale and enhancing cross-navigation between the different services.
- If the fact box – and the features that may follow – becomes a pervasive and popular feature, Google’s participation in making information and knowledge accessible, in defining its shape, scope, and relevance, will be further extended. This is a reason to worry a bit more, not because the Google tools as such are a danger, but simply because of the levels of institutional and economic concentration the Internet has enabled. The company has become what Michel Callon calls an “obligatory passage point” in our relation to the Web and beyond; the knowledge graph has the potential to exacerbate the situation even further.
This is a development that looks like another element in the war for dominance on the Web that is currently fought at a frenetic pace. Since the introduction of actions into Facebook’s social graph, it has become clear that approaches based on ontologies and concept modelling will play an increasing role in this. In a world mediated by screens, the technological control of meaning – the one true metamedium – is the new battleground. I guess that this is not what Berners-Lee had in mind for the Semantic Web…
While scholars often underline their commitment to non-deterministic conceptions of “effects”, models of causality in the human and social sciences can still be a bit simplistic sometimes. But a more subtle approach to causality would have to concede that, while most often cumulative and contradictory, lines of causation can sometimes be quite straightforward. Just consider this example from Commensuration as a Social Process, a great text from 1998 by Espeland and Stevens:
Faculty at a well-regarded liberal arts college recently received unexpected, generous raises. Some, concerned over the disparity between their comfortable salaries and those of the college’s arguably underpaid staff, offered to share their raises with staff members. Their offers were rejected by administrators, who explained that their raises were ‘not about them.’ Faculty salaries are one criterion magazines use to rank colleges. (p.313)
This is a rather direct effect of ranking techniques on something very tangible, namely salary. But the relative straightforwardness of the example also highlights a bifurcation of effects: faculty gets paid more, staff less. The specific construction of the ranking mechanism in question therefore produces social segmentation. Or does it simply reinforce the existing segmentation between faculty and staff that lead college evaluators to construct the indicators the way they did in the first place? Well, there goes the simplicity…
Simondon’s Du mode d’existence des objets techniques from 1958 is a most wondrous book. It is not only Simondon’s theory of technology in itself that fascinates me, but rather the intimate closeness with particular technical objects that resonates through the whole text and marks a fundamental break with the greek heritage of thinking about technology as a unified and coherent force. When Simondon reasons over numerous pages on the difference between a diode and a triode, he accords significance to something that was considered insignificant by virtually every philosopher in history. By conferring a sense of dignity to technology, a certain profoundness, he is able to see heterogeneity and particularity where others before him just saw the declinations of the singular principle of techné. In a distinctly beautiful passage, Simondon argues that “technological thinking” itself is not totalizing but fragmenting:
“L’élément, dans la pensée technique, est plus stable, mieux connu, et en quelque manière plus parfait que l’ensemble ; il est réellement un objet, alors que l’ensemble reste toujours dans une certaine mesure inhérent au monde. La pensée religieuse trouve l’équilibre inverse : pour elle, c’est la totalité qui est plus stable, plus forte, plus valable que l’élément.” (Simondon 1958, p. 175)
And my translation:
“In technological thinking, it is the element that is more stable, better known and – in a certain sense – more perfect than the whole; it is truly an object, whereas the whole always stays inherent to the world to a certain extend. Religious thinking finds the opposite balance: here, it is the whole that is more stable, stronger, and more valid than the element.”
Philosophical thinking, according to Simondon, should strive to situate itself in the interval that separates the two approaches, technological thinking and religious thinking, concept and idea, plurality and totality, a posteriori and a priori. Here, the question of How? is not subordinate to the question of Why? because it is the former that connects us to the world that we inhabit as physical beings. Understanding technology means understanding how the two levels relate and constitute a world. There are two forms of ethics and two forms of knowledge that must be combined both intellectually and practically. Simondon obviously strives to do just that. I would argue that Philip Agre’s concept of critical technical practice is another attempt at pretty much the same challenge.
In August 2010, Edinburgh Sociologist Donald MacKenzie (whose book An Engine, not a Camera is an outstanding piece of scholarship) wrote an article in the Financial Times titled Unlocking the Language of Structured Securities where he discusses a software suite for financial analysis called Intex and compares it to a language that allows to see and interact with the world in certain ways rather than others. MacKenzie describes his first encounter with Intex as a moment of revelation that quickly turned into doubt:
The psychological effect was striking: for the first time, I felt I could understand mortgage-backed securities. Of course, my new-found confidence was spurious. The reliability of Intex’s output depends entirely on the validity of the user’s assumptions about prepayment, default and severity. Nevertheless, it is interesting to speculate whether some of the pre-crisis vogue for mortgage-backed securities resulted from having a system that enabled neophytes such as myself to feel they understood them.
While MacKenzie does not go as far as imputing the recent financial crisis to a piece of software, he points out that Intex is not recursive in its mode of analysis: when evaluating a complex financial asset, for example one of the now (in)famous CDOs that are made up of other assets, themselves combining further values, and so on, Intex does not follow the trail down to the basic entities (the individual mortgage) but calculates risk only from the rating of the asset in question. MacKenzie argues that Goldman-Sachs’ 2006 decision to basically get out of mortgage-based securities may well be a result of their commitment to go beyond available tools by implementing a (very costly) “bottom-up” approach that builds its evaluation of an asset by calculating up from the basic units of value. The card-house character of these financial instruments could become visible by changing tools and thereby changing perspective or language. Software makes it possible to implement very different practices or languages and to make them pervasive; but how does a company chose one strategy over another? What are the organizational and “cultural” factors that lead Goldman-Sachs to change its approach? These may be the truly challenging questions here, although they may never get answered. But they lead to a methodological lesson.
The particular strength of systems like Intex lies in their capacity to black-box evaluation strategies behind a neat interface that allows users to immediately operate on the underlying models, weaving these models into their decisions and practices. Conceptually, we understand the ways in which software shapes action better and better but the empirical complexity of concrete settings is positively daunting even outside of the realm of financial markets. What I take from MacKenzie’s work is that in order to understand the role of software, we have to be very familiar with the specific terrain a system is embedded in, instead of bringing overarching assumptions to the table. Software is a means for building structure and this building is always happening in particular organizational settings that are certainly caught up in larger trends but also full of local challenges, politics, and knowledge. Programs are at the same time structuring backdrop practice and part of a strategic repertoire that actors dispose of.
The case of financial software indicates that market behavior standardizes around available tools which leads to the systemic delegation of certain decision processes to software makers. This may result in a particular type of herd behavior and potentially in imbalance and crisis. Somewhat ironically, it is Goldman-Sachs that showed the potential of going against the grain by questioning programmed wisdom. That the company recently paid $550M in fines for abusing their analytical advantage by betting against a CDO they were selling to customers as an investment indicates that ethics and cunning are unfortunately two pair of shoes…