Category Archives: privacy
Social media platforms have become really huge. They have very large numbers of users, who share very large numbers of messages, images, videos, and so forth. They have a whole lot of spare cash, either from advertising revenue or from IPOs. They have not only become an intrinsic part of interpersonal communication and of the way we inform ourselves, but much of what news organizations report nowadays seems to be about who tweets what to whom with what effect. The controversy around how Facebook editorializes the newsfeed and trending topics is only the latest indicator for the enormous imprint on the circulation of information and ideas the company now has. The European Commission has recently launched a public consultation on the role of platforms, in reaction to two reports by the German and French governments on the topic.
One of the key terms in all of this is “transparency”. Often this concerns moments of decision-making such as ranking, filtering, pricing, suggesting, and so forth. And often the debate focuses on the role of algorithms vs moments of human discretion (the opposition is problematic in many ways, but that’s another topic). Demands for transparency then focus on “opening the black box” and Facebook’s recently published guidelines fit into this framework. But there is another aspect to transparency that is less often evoked, which concerns the question “what is actually going on in these platforms?”. This goes beyond the question of algorithms to include the very communicational makeup of these systems (interfaces, functions, etc.) and, even more importantly, the concrete results of large masses of users actually integrating these technical elements into their practices. Transparency, in that sense, is not simply concerned with knowledge about the system’s design, but with the ways users and technical infrastructure form an integrated whole that produces specific outcomes in terms of circulation of information and ideas. One way to understand this integrated whole a little better is empirical research, whether it happens on the micro level in the form of ethnography, on the meso level around specific issues, or on the macro level in the form of large statistical aggregations. Empirical research is, ultimately, the only way to understand what the editorializing (which includes the full design of the service, not just filtering) of Facebook and other companies actually means in terms of outcomes or effects.
But empirical research on large online platforms is getting more and more difficult. Last year, Facebook removed a number of functions from their API, and research applications like Netvizz lost a part of their capacity to produce transparency by giving researchers the means to do (a certain kind of data-driven) empirical research. The latest case is Instagram. Already a year ago, the company announced that every application would have to go through a permission review to be allowed to continue. My own Instagram Hashtag Explorer (which I renamed to Visual Tagnet Explorer – VTE – to conform to the app guidelines which prohibit the use of the company name) has been relying on API data to help researchers understand how people use Instagram to produce visual and textual accounts of issues, events, places, companies, and so forth. After submitting the app for review, I today received notification that the application was denied. A detailed description of the tool and a screencast that attempted to connect the tool – in not totally absurd ways I think – to the “accepted use cases” were not good enough to yield any more commentary than this:
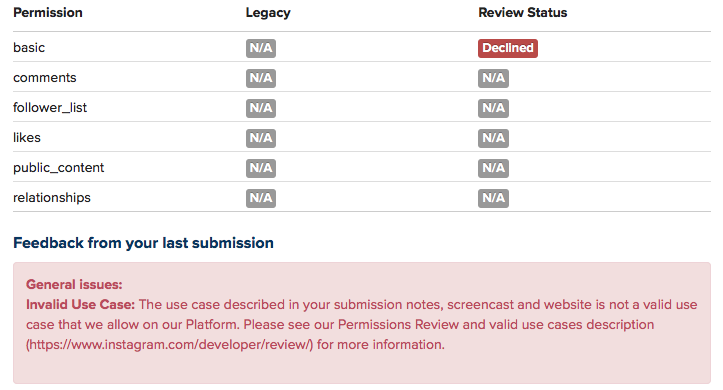
Now, we can lament about lost programming time (it wasn’t much fortunately) and research projects that will run into trouble, but the real problem, I think, connects to the question of transparency as I framed it above. Sure, a little script would never have solved the problem how to understand platform dynamics, but it was a little step on the ladder. There are certainly other means to do research and even data-driven research will be possible through scraping. But I wonder how far ethnographic studies, for example, are able to address questions concerning macro effects. And I wonder how sustainable and scalable scraping is. Sure, we can play the cat and mouse game with automatic bot detection and evolving interfaces, but is this going to produce the large window on these platforms we need to really understand them in terms of their effects on publicness? Maybe I’ll make some changes to VTE and submit it again, even though I have basically no feedback to go on. Maybe it will pass. But the larger problem will remain.
What is needed, I think, is something different. Yes, data retrieval, even by academic researchers, raises concerns about privacy. But privacy is not the only legitimate political aspiration, here. What, indeed, about publicness? What about the need to know about stuff in order to make democratic decisions? How to even begin to think about regulation if real outcomes are getting more and more difficult to assess? This is why I want to iterate an argument that I already tried to make during the EC’s public consultation: we need a legal framework to guarantee at least some access to API data, at least for some people. It is certainly nice that companies start research collaborations, but these fit of course into a sanitized view on their services. We therefore need, I think, something that is able to express the public’s legitimate interest to know “what’s going on” and access to API data is, in my view, a more promising avenue than the forms of purely technical or operational transparency that are often discussed. Fair use principles, for example concerning copyright, exist in academia because there is a belief that research that is not beholden to corporate interest performs a function in public life that is worth protecting. Can we imagine something similar with API data? A legally protected means to do research into these platforms? To find a compromise between privacy and publicness, we would have to find a way to distinguish between “disinterested” research and other applications. But technically, everything is in place. The APIs are there, even if they are closing down after their utility for growing the ecosystem has expired and selling data to analytics companies is becoming a revenue stream. The tools are in place and the researchers are starting to understand how to use them in useful ways. Compared to the daunting legal battles around antitrust measures, it’s almost banal to make this a reality.
Even if this idea proves to be a pipe dream, I think that we have to widen the debate around the values to take into account when criticizing the role of platforms in public life. Privacy is important, but public understanding of outcomes is as well.
One of the reasons I started to develop the netvizz application, was to get better insights into how Facebook envisions exchange of data and functionality with third party developers. From the beginning, I was quite amazed how much data a third-party app could actually get from the platform – not only about the users that actually install an app, but also about their friends and the groups they are members of. I hope to provide a systematic account of what I’ve learned at some point in the future. But today, I want to discuss a particular element in some more detail, the “read_stream” permission.
To introduce the matter, a couple of points concerning the Facebook APIs as such: every application written by a third-party developer requires a logged in user and this user defines the “scope” of data access the running instance of the application can get – remember that applications are generally used by many users, so the data gleaned from individual scopes can be combined. Applications have to explicitly ask for permission to access certain items and Facebook provides extensive documentation on the permission system, the profile properties, and a set of extended permissions. Users are asked to grant these permissions when they first start an app. This is the permission dialogue for netvizz:

Netvizz currently asks for the following permissions: user_status, user_groups, friends_likes, user_likes, and read_stream. When installing, you cannot refuse individual elements that are not considered “extended permissions”, only decide to not use the app at all. The user_status is actually superfluous and will be removed in the next iteration. The user_groups permission is needed to access group data and both _likes permissions are used for netvizz’ like network functionality.
Now, working on a couple of new features over the last months, I started to get more interested in posts because they have probably become the closest thing to a “carrier of publicness” on the Facebook platform. I was quite amazed how easy it was to extract large numbers of users and (some) of their data from pages – both likes and comments users make on post on or by pages are in principle up for grabs. When doing some housekeeping recently, I noticed that some of the “engagement” metrics netvizz had provided for users’ friends in earlier versions were either broken or outdated and I decided to simply count the number of likes and posts friends make to replace the older metrics. I expected to only be able to read likes – through the friends_likes permission – and public posts. This was indeed true: in the beginning, all I got were public posts. Because I could get much more data through the Graph API Explorer, a developer sandbox that asks for all permissions by default (which can be changed, a great way to explore the permission structure), I discovered the read_stream permission.
The read_stream permission is presented by Facebook in the following way: “Provides access to all the posts in the user’s News Feed and enables your application to perform searches against the user’s News Feed.” It is a so-called “extended permission”, the developer doc noting that “Extended Permissions give access to more sensitive info and the ability to publish and delete data”. And, indeed, when asking for read_stream in netvizz, I suddenly got access to many more posts made by my friends, mostly going from “none” to “a lot”. From what I could gather after some random testing was that I basically got access to all of the activities from my friends that would show up in my newsfeed, without the “top stories” filter. Because many things have the status of “post”, I could get a rather detailed (and timestamped) account of what my friends are doing on the platform. You can check out your own “posts” feed by following this link into the Graph API Explorer. Because comments and likes by users who you are not friends with on posts by somebody you are friends with also show up in your news feed, the read_stream permission allows to capture their activity as well. Facebook seems to be aware of this: because read_stream is an extended permission it gets its own permission dialogue and can actually be skipped:

This is a good thing, but the wording seems a bit sparse: “Posts in your newsfeed” actually translates to “a minute account of your friends’ activities”. Granted, buried in the privacy settings is an option that allows us to modify more generally what information we share with the apps other people use, and these are the default settings:

It’s the “Activities, interests, things I like” option that allows the read_stream permission to work its magic. The people I am friends with on the platform are generally a rather privacy conscious bunch, but I could get the posts from most of them.
This is not a privacy scandal of any sort, measures are in place, but one can still make a couple of points:
- Apps as means for data capture are clearly not discussed enough. For serious data collection, however, going through the API is clearly the way to go and we need to pay more attention to this.
- Again and again: defaults matter. As seen above, the data available to apps used by friends is quite extensive with default settings.
- Again and again: language matters. The read_stream permission dialogue is certainly not explicit enough. Also: why is “app privacy” not in the privacy tab here?
- When we log into a third party site with our Facebook login, we are basically running an app. May be worth pondering what data we are shipping over.
Exploring APIs as important actors in the privacy debate and beyond is crucial. It’s often complicated work, though, and I hope that the developer community can help with that work a bit. It would be highly useful, I think.
German publisher Heise Verlag is an international curiosity. It publishes a small number of highly influential computer-related magazines that give a voice to a tech ethos that is at the same time extremely competent in the subject matter (I’ve been a steady subscriber to c’t magazin for over 15 years now, and I am still baffled sometimes just how good it is) and very much aware of the social and political implications of computing (their online magazine Telepolis testifies to that).
Data protection and privacy are long-standing concerns of the heise editors and true to a spirit of society-oriented design, they have introduced a concept as well as a technical implementation of a two-step “like” button. Such buttons, by Facebook or other companies, have of course become a major vector of user-tracking on the Web. By using an iframe, every button loads some code from Facebook’s server and sends the referring url (e.g. http://nytimes.com/articlename/blabla) as an information. The iframe being hosted on the facebook.com domain, cross-site privacy protections can be circumvented, the url information connected to an identifier cookie and, consequently, to a user account. Plugins like the Priv3 project block these mechanisms but a) users have to have a heightened level of awareness to even consider installing something like this and b) the plugin interferes with convenient functions like Google search preferences.
 Heise’s suggestion, which they already implemented on their own sites, is simple: websites can download a small bit of code that implements a two-step procedure: the “like” button is greyed out after the page first loads and there is no tracking happening. A first click on the button loads the “real” Facebook code, and the second click provides the usual functionality. The solution is very simple to implement and really a very minor inconvenience. Independently from the debate whether “like” buttons and such add any real value to the Web, this example shows that “social” features like these can be designed in a way that does not necessarily lead to pervasive user tracking.
Heise’s suggestion, which they already implemented on their own sites, is simple: websites can download a small bit of code that implements a two-step procedure: the “like” button is greyed out after the page first loads and there is no tracking happening. A first click on the button loads the “real” Facebook code, and the second click provides the usual functionality. The solution is very simple to implement and really a very minor inconvenience. Independently from the debate whether “like” buttons and such add any real value to the Web, this example shows that “social” features like these can be designed in a way that does not necessarily lead to pervasive user tracking.
The echo to this initiative has been very strong (check the Slashdot discussion here), especially in Germany, where privacy (or rather Datenschutz, a concept less centered on the individual but rather on the role of data in society) is an intensely debated issue, due to obvious historical reasons. Facebook apparently threatened to blacklist heise.de at a point, but has since then backpedaled. After all, c’t magazin prints around 600.000 issues of every number and is extremely influential in the German (and Dutch!) computer landscape. I am very curious to see how this story unfolds, because let’s be clear: Facebook’s earning potential is closely tied to its capacity to capture, enrich, and analyze user data.
This initiative – and the Heise ethos in general – underscores that a “respectable” and sober engineering culture does not exclude an explicit normative stance on social and political issues. And is shows that this stance can be translated into technical models, implemented, and shared, both as an idea and as code.
Programmable web just pointed to a really interesting mashup competition. Sunlight labs announced the Apps for America contest and the idea is to attract programmers that will use a series of data APIs to “make Congress more accountable, interactive and transparent”. Among the criteria two stand out:
- Usefulness to constituents for watching over and communicating with their members of Congress
- Potential impact of ethical standards on Congress
The design goal is accountability and that indeed is a perfect case for society oriented design. While people in Europa love to scold the US for their lack of data protection and privacy laws, just looking at the APIs the contest proposes to use makes me salivate for something similar in France. If you look at the Capitol Words API for example, just imagine the kind of discourse analysis one could build on that. Representations of what is said in Congress that make the data digestable and bring at least some of the debate potentially closer to citizens. The whole thing is just a really great idea…
Continuing in the direction of exploring statistics as an instrument of power more characteristic of contemporary society than means of surveillance centered on individuals, I found a quite beautiful citation by French sociologist Gabriel Tarde in his Les Lois de l’imitation (1890/2001, p.192f):
Si la statistique continue à faire des progrès qu’elle a faits depuis plusieurs années, si les informations qu’elle nous fournit vont se perfectionnant, s’accélérant, se régularisant, se multipliant toujours, il pourra venir un moment où, de chaque fait social en train de s’accomplir, il s’échappera pour ainsi dire automatiquement un chiffre, lequel ira immédiatement prendre son rang sur les registres de la statistique continuellement communiquée au public et répandue en dessins par la presse quotidienne.
And here’s my translation (that’s service, folks):
If statistics continues to make the progress it has made for several years now, if the information it provides us with continues to become more perfect, faster, more regular, steadily multiplying, there might come the moment where from every social fact taking place springs – so to speak – automatically a number that would immediately take its place in the registers of the statistics continuously communicated to the public and distributed in graphic form by the daily press.
When Tarde wrote this in 1890, he saw the progress of statistics as a boon that would allow a more rational governance and give society the means to discuss itself in a more informed, empirical fashion. Nowadays, online, a number springs from every social fact indeed but the resulting statistics are rarely a public good that enters public debate. User data on social networks will probably prove to be the very foundation of any business that is to be made with these platforms and will therefore stay jealously guarded. The digital town squares are quite private after all…