Category Archives: database
The New York Times is not only a very good newspaper, it is also a really, really interesting archive that provides search access to all articles since 1851 via a pretty nice API. I’ve been meaning to play with it for some time, but things were extremely busy this year. But yesterday, I had some time in the evening and looked into the system a little bit and wrote a couple of scripts to try out some quick ideas.
While the API has all kinds of interesting things – in particular access to the Times’ controlled vocabulary – I am most interested in the article archive and the different possibilities to explore it. Understandably, the API does not provide the full text of articles; but it does search in the full text and for every found article it delivers quite a number of interesting things. Here is an example of what the returned data for a query (“guantanamo bay”) looks like:
While there are many things to go with, I found the manually attributed (and controlled) keywords to be particularly interesting. So I decided to explore and visualize how a particular subject evolves over time inside of this classificatory structure. Because the request rate for the search API is quite generous (10/s, 10K/day) I wrote a short PHP script (grab.php) that grabs this metadata for every article corresponding to a given search query. It simply downloads the data and stores it in a bunch of JSON files. A second script (analyze.php) then parses these files and creates a simple CSV file that can then be visualized with something like R (which I started working with some weeks ago, much easier than I thought, lots of fun).
With the help of the amazing ggplot2 library in R, using “guantanamo bay” as query, I quickly got a first result (click for larger image):
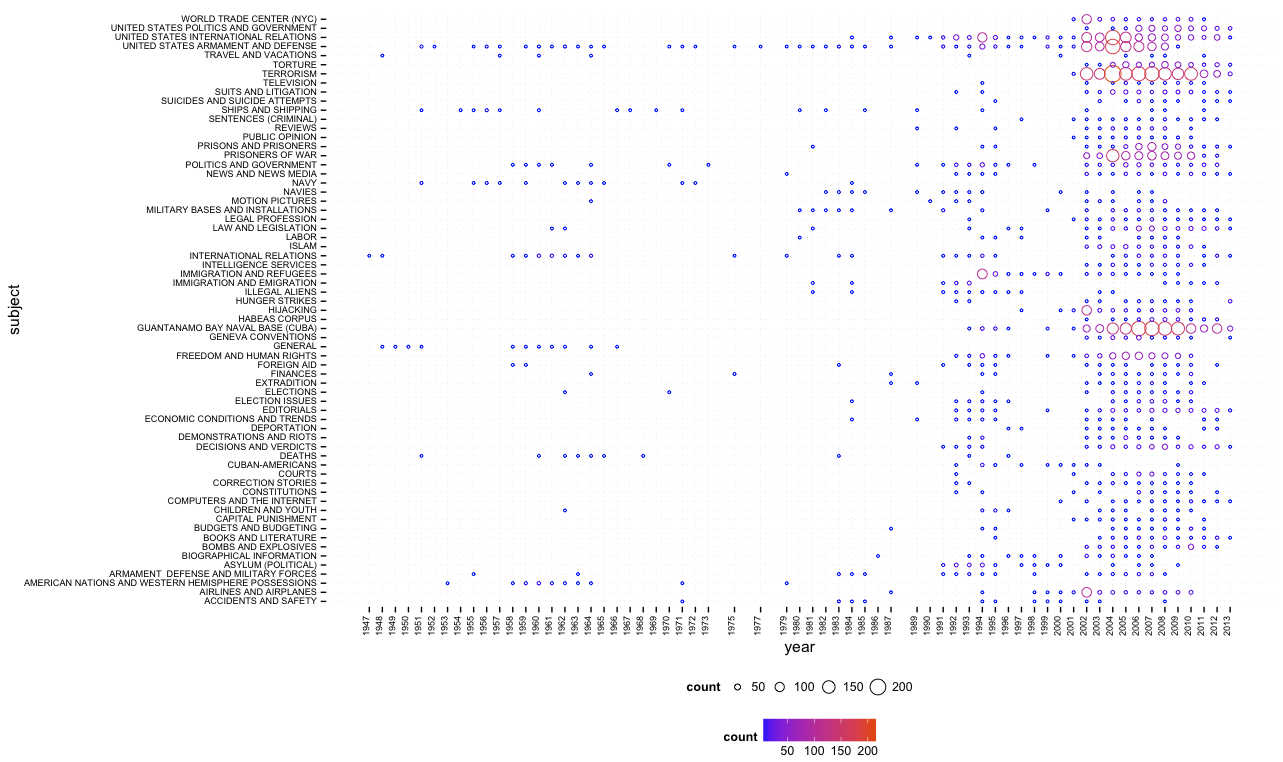
One can quite easily see that Guantanamo Bay was discussed in the 1990s in terms of immigration, asylum, and similar terms, while the current frame (terrorism, etc.) appears just after 9/11. While this script (bubbles.R) provides overview, a second one (bubbles_numbers.R) provides a combination of bubbles and numbers (click for larger image):

There is certainly much more interesting stuff to do with this data (e.g. different types of normalization, taking into account word count and page number, etc.) and I’ll hopefully come back to this in more detail in the future. In the meantime, all scripts can be found here.
Update June 2, 2013:
I’ve added a network export feature to the scripts on github. Generated network files are not limited to subject tags, but include people, organizations, locations, and creative works (e.g. books or movies). If two tags appear on the same article, a link is created and the more often they appear together, the stronger the connection. Here’s a quick visualization, made with gephi, of the most common people (red), organizations (green), and locations (blue) for the query “climate change” (click for larger image):

One of the reasons I started to develop the netvizz application, was to get better insights into how Facebook envisions exchange of data and functionality with third party developers. From the beginning, I was quite amazed how much data a third-party app could actually get from the platform – not only about the users that actually install an app, but also about their friends and the groups they are members of. I hope to provide a systematic account of what I’ve learned at some point in the future. But today, I want to discuss a particular element in some more detail, the “read_stream” permission.
To introduce the matter, a couple of points concerning the Facebook APIs as such: every application written by a third-party developer requires a logged in user and this user defines the “scope” of data access the running instance of the application can get – remember that applications are generally used by many users, so the data gleaned from individual scopes can be combined. Applications have to explicitly ask for permission to access certain items and Facebook provides extensive documentation on the permission system, the profile properties, and a set of extended permissions. Users are asked to grant these permissions when they first start an app. This is the permission dialogue for netvizz:

Netvizz currently asks for the following permissions: user_status, user_groups, friends_likes, user_likes, and read_stream. When installing, you cannot refuse individual elements that are not considered “extended permissions”, only decide to not use the app at all. The user_status is actually superfluous and will be removed in the next iteration. The user_groups permission is needed to access group data and both _likes permissions are used for netvizz’ like network functionality.
Now, working on a couple of new features over the last months, I started to get more interested in posts because they have probably become the closest thing to a “carrier of publicness” on the Facebook platform. I was quite amazed how easy it was to extract large numbers of users and (some) of their data from pages – both likes and comments users make on post on or by pages are in principle up for grabs. When doing some housekeeping recently, I noticed that some of the “engagement” metrics netvizz had provided for users’ friends in earlier versions were either broken or outdated and I decided to simply count the number of likes and posts friends make to replace the older metrics. I expected to only be able to read likes – through the friends_likes permission – and public posts. This was indeed true: in the beginning, all I got were public posts. Because I could get much more data through the Graph API Explorer, a developer sandbox that asks for all permissions by default (which can be changed, a great way to explore the permission structure), I discovered the read_stream permission.
The read_stream permission is presented by Facebook in the following way: “Provides access to all the posts in the user’s News Feed and enables your application to perform searches against the user’s News Feed.” It is a so-called “extended permission”, the developer doc noting that “Extended Permissions give access to more sensitive info and the ability to publish and delete data”. And, indeed, when asking for read_stream in netvizz, I suddenly got access to many more posts made by my friends, mostly going from “none” to “a lot”. From what I could gather after some random testing was that I basically got access to all of the activities from my friends that would show up in my newsfeed, without the “top stories” filter. Because many things have the status of “post”, I could get a rather detailed (and timestamped) account of what my friends are doing on the platform. You can check out your own “posts” feed by following this link into the Graph API Explorer. Because comments and likes by users who you are not friends with on posts by somebody you are friends with also show up in your news feed, the read_stream permission allows to capture their activity as well. Facebook seems to be aware of this: because read_stream is an extended permission it gets its own permission dialogue and can actually be skipped:

This is a good thing, but the wording seems a bit sparse: “Posts in your newsfeed” actually translates to “a minute account of your friends’ activities”. Granted, buried in the privacy settings is an option that allows us to modify more generally what information we share with the apps other people use, and these are the default settings:

It’s the “Activities, interests, things I like” option that allows the read_stream permission to work its magic. The people I am friends with on the platform are generally a rather privacy conscious bunch, but I could get the posts from most of them.
This is not a privacy scandal of any sort, measures are in place, but one can still make a couple of points:
- Apps as means for data capture are clearly not discussed enough. For serious data collection, however, going through the API is clearly the way to go and we need to pay more attention to this.
- Again and again: defaults matter. As seen above, the data available to apps used by friends is quite extensive with default settings.
- Again and again: language matters. The read_stream permission dialogue is certainly not explicit enough. Also: why is “app privacy” not in the privacy tab here?
- When we log into a third party site with our Facebook login, we are basically running an app. May be worth pondering what data we are shipping over.
Exploring APIs as important actors in the privacy debate and beyond is crucial. It’s often complicated work, though, and I hope that the developer community can help with that work a bit. It would be highly useful, I think.
Edit: slides
On Thursday, I will be giving a talk at the “The Lived Logics of Database Machinery” workshop, organized by computational culture, which will take place at the Wellcome Collection Conference Centre in London, from 10h to 17h30. I am very much looking forward to this, although I’ll be missing a couple of days from the currently ongoing DMI summer school. This is what I will be talking about:
ORDER BY column_name. The Relational Database as Pervasive Cultural Form
This contribution starts from the observation that, in a way similar to the computational equivalence of programming languages, the major types of database models (network, relational, object-oriented, etc.) and implementations are all able to store and manage a very large variety of data structures. This means that most data structures could be modeled, in one way or another, in almost any existing database system. So why have there been so many intense debates about how to conceive and build database systems? Just like with programming languages, the specific way a database system embeds an abstract concept in a set of concrete methods and mechanisms for specifying, accessing, and manipulating datasets is significant. Different database models and implementations imply different ways of “thinking” data organization, they vary in performance, robustness, and “logistics” (one of the reasons why Oracle’s product succeeded well in the enterprise sector in the 1980s, despite its lack of certain features, was the ability to make backups of a running database), and they provide different modes of interaction with both the data and the system.
The central vector of differentiation, however, is the question how users “see” the data: during the “database debates” of the 1970s and 1980s the idea of the database as a set of tables (relational model) was put in opposition to the vision of the database as a network of records (network model). The difference between the two concerned not only performance, flexibility, and complexity, but also the crucial question who the users of these systems would be in the first place. The supporters of the network model clearly saw the programmer as the target audience for database systems but the promoters of the much simpler relational model and its variants imagined “accountants, engineers, architects, and urban planners” (Chamberlin and Boyce 1974) to directly interact with data by means of a simple query language. While this vision has not played out, according to Michael Stonebreaker’s famous observation, SQL (the most popular, albeit impure implementation of Codd’s relational ideas) has indeed become “intergalactic data-speak” (most packages on the market provide SQL interfaces) and this standardization has strongly facilitated the penetration of database systems into all corners of society and contributed to a widespread “relational view” of data organization and manipulation, even if data modeling is still mostly in expert hands.
The goal of this contribution is to examine this “relational view” in terms of what Jack Goody called the “modes of thought” associated with writing, and in particular with the list form, which “encourages the ordering of the items, by number, by initial sound, by category, etc.” (Goody 1977). As with most modern technologies, the relational model implies a complex set of constraining and enabling elements. The basic structural unit, the “relation” (what most people would simply call a table) disciplines data modeling practices into logical consistency (tables only accept tuples/rows with the same attributes) while remaining “semantically impoverished” (Stonebreaker 1993). Heterogeneity is purged from the relational model on the level of modeling, especially if compared to navigational approaches (e.g. XPath or DOM), but the “set-at-a-time” retrieval concept, combined with a declarative query language, affords remarkable flexibility and expressiveness on the level of data selection. The relational view thus implies an “ontology” consisting of regular, uniform, and only loosely connected objects that can be ordered in a potentially unlimited number of ways at the time of retrieval (by means of the query language, i.e. without having to program explicit retrieval routines). In this sense, the relational model perfectly fits the qualities that Callon and Muniesa (2005) attribute to “powerful” calculative agency: handle a long list of diverse entities, keep the space of possible classifications and reclassifications largely open, multiply possible hierarchies and classifications. What database systems then do, is bridging the gap between these calculative capacities and other forms of agency by relating them to different forms of performativity (e.g., in SQL speak, to SELECT, TRIGGER, and VIEW).
While the relational model’s simplicity has led to many efforts to extend or replace it in certain application areas, its near universal uptake in business and government means that the logistics of knowledge and ordering implied by the relational ontology resonate through the technological layers and database schemas into the domains of management, governance, and everyday practices.
I will argue that the vision of the “programmer as navigator” trough a database (Bachman 1973) has, in fact, given way to a setting where database consultants, analysts, and modelers sit between software engineering on the one side and management on the other, (re)defining procedures and practices in terms of the relational model. Especially in business and government sectors, central forms of management and evaluation (reporting, different forms of data analysis, but also reasoning in terms of key performance indicators and, more generally, “evidence based” management) are directly related to the technological and cognitive standardization effects derived from the pervasiveness of relational databases. At the risk of overstretching my argument, I would like to propose that Thrift’s (2005) “knowing capitalism” indeed knows (largely) in terms of the relational model.
Yesterday, Google introduced a new feature, which represents a substantial extension to how their search engine presents information and marks a significant departure from some of the principles that have underpinned their conceptual and technological approach since 1998. The “knowledge graph” basically adds a layer to the search engine that is based on formal knowledge modelling rather than word statistics (relevance measures) and link analysis (authority measures). As the title of the post on Google’s search blog aptly points out, the new features work by searching “things not strings”, because what they call the knowledge graph is simply a – very large – ontology, a formal description of objects in the world. Unfortunately, the roll-out is progressive and I have not yet been able to access the new features, but the descriptions, pictures, and video paint a rather clear picture of what product manager Johanna Wright calls the move “from an information engine to a knowledge engine”. In terms of the DIKW model (Data-Information-Knowledge-Wisdom), the new feature proposes to move up a layer by adding a box of factual information on a recognized object (the examples Google uses are the Taj Mahal, Marie Curie, Matt Groening, etc.) next to the search results. From the presentation, we can gather that the 500 million objects already referenced will include a large variety of things, such as movies, events, organizations, ideas, and so on.

This is really a very significant extension to the current logic and although we’ll need more time to try things out and get a better understanding of what this actually means, there are a couple of things that we can already single out:
- On a feature level, the fact box brings Google closer to “knowledge engines” such as Wolfram Alpha and as we learn from the explanatory video, this explicitly includes semantic or computational queries, such as “how many women won the Nobel Prize?” type of questions.
- If we consider Wikipedia to be a similar “description layer”, the fact box can also be seen as a competitor to everybody’s favorite encyclopedia, which is a further step into the direction of bringing information directly to the surface of the results page instead of simply referring to a location. This means that users do not have to leave the Google garden to find a quick answer. It will be interesting to see whether this will actually show up in Wikipedia traffic stats.
- The introduction of an ontology layer is a significant departure from the largely statistical and graph theoretical methods favored by Google in the past. While features based on knowledge modelling have proliferated around the margins (e.g. in Google Maps and Local Search), the company is now bringing them to the center stage. From what I understand, the selection of “facts” to display will be largely driven by user statistics but the facts themselves come from places like Freebase, which Google bought in 2010. While large scale ontologies were prohibitive in the past, a combination of the availability of crowd-sourced databases (Wikipedia, etc.), the open data movement, better knowledge extraction mechanisms, and simply the resources to hire people to do manual repairs has apparently made them a viable option for a company of Google’s size.
- Competing with the dominant search engine has just become a lot harder (again). If users like the new feature, the threshold for market entry moves up because this is not a trivial technical gimmick that can be easily replicated.
- The knowledge graph will most certainly spread out into many other services (it’s already implemented in the new Google Docs research bar), further boosting the company’s economies of scale and enhancing cross-navigation between the different services.
- If the fact box – and the features that may follow – becomes a pervasive and popular feature, Google’s participation in making information and knowledge accessible, in defining its shape, scope, and relevance, will be further extended. This is a reason to worry a bit more, not because the Google tools as such are a danger, but simply because of the levels of institutional and economic concentration the Internet has enabled. The company has become what Michel Callon calls an “obligatory passage point” in our relation to the Web and beyond; the knowledge graph has the potential to exacerbate the situation even further.
This is a development that looks like another element in the war for dominance on the Web that is currently fought at a frenetic pace. Since the introduction of actions into Facebook’s social graph, it has become clear that approaches based on ontologies and concept modelling will play an increasing role in this. In a world mediated by screens, the technological control of meaning – the one true metamedium – is the new battleground. I guess that this is not what Berners-Lee had in mind for the Semantic Web…
While there are probably a lot of people that have stumbled over the Google Ngram Viewer, it is safe to assume that fewer have read the paper (Science, January 2011) by Michel et al. that documents the project and gives a good idea of the kind of “big iron” science we can expect to capture quite a lot of attention over the next couple of years. According to the (14, one being “The Google Books Team”, another Steven Pinker) authors, the projet – fittingly termed culturomics – is based on a sample of 5,195,769 books, which apparently represents roughly 4% of all the books ever published. They easiest way to show the scope of what the researchers aim to do is quoting the abstract in full:
We constructed a corpus of digitized texts containing about 4% of all books ever printed. Analysis of this corpus enables us to investigate cultural trends quantitatively. We survey the vast terrain of ‘culturomics,’ focusing on linguistic and cultural phenomena that were reflected in the English language between 1800 and 2000. We show how this approach can provide insights about fields as diverse as lexicography, the evolution of grammar, collective memory, the adoption of technology, the pursuit of fame, censorship, and historical epidemiology. Culturomics extends the boundaries of rigorous quantitative inquiry to a wide array of new phenomena spanning the social sciences and the humanities.
Next to the sheer size of the corpus, there are several things that are quite remarkable with this project:
1) While the paper is full of graphs, it is immensely interesting that many of the measurements taken can be “reenacted” with the Ngram Viewer. In a passage that diagnoses “a greater focus on the present” in more recent publications, the authors show that the half-life (i.e. the number of years it takes for a date to get to half the frequency value of an initial peak) of dates gets much shorter over time. We can easily graph the result ourselves: This possibility to query the data ourselves (as well as the comprehensive data sharing) represents quite a change in how we can relate to the results as scholars and while only the most well-funded projects will be able to provide a “companion” data-tool, there is a real epistemological shift underway. From a teaching perspective, the hands-on approach may actually be even more valuable.
This possibility to query the data ourselves (as well as the comprehensive data sharing) represents quite a change in how we can relate to the results as scholars and while only the most well-funded projects will be able to provide a “companion” data-tool, there is a real epistemological shift underway. From a teaching perspective, the hands-on approach may actually be even more valuable.
2) We increasingly have very comprehensive available data sets that can be used as concept markers in very different contexts. In this case, the authors used 740.000 names of persons from Wikipedia to study different aspects of fame. But one could easily imagine using GeoNames to perform a similar survey of the ebb and fall of geographic prominence. I am quite sure that linguists will soon bring together the Ngram data with WordNet to study concept evolution and other things.
3) While the examples developed in the article are fascinating – and there will certainly be many more – the epistemological horizon is quite vague for the moment. There is no question that historical linguistics will have a field day plunging into the data, but the intellectual rationale behind the project of culturomics is a bit thin for the moment:
Culturomics is the application of high-throughput data collection and analysis to the study of human culture. Books are a beginning, but we must also incorporate newspapers, manuscripts, maps, artwork, and a myriad of other human creations. Of course, many voices—already lost to time— lie forever beyond our reach.
Culturomic results are a new type of evidence in the humanities. As with fossils of ancient creatures, the challenge of culturomics lies in the interpretation of this evidence.
I would argue that it is not so much the interpretation of evidence that represents a challenge but the integration of these new computer-based approaches into meaningful research agendas that ask non-trivial questions. While it may be interesting to be able to attach a number to the competence of Nazi censorship efforts, this competence was never very much in doubt and while numbers and graphs may confer an aura of scientific respectability, the findings will most probably not add anything to our understanding of national socialism.
While it is increasingly unpopular to cite Snow’s Two Cultures, this early proposal for a quantitative approach to culture (in its historic dimension) will give rise to all kinds of polemics, misunderstandings, and demarkation efforts. The public availability of a query tool is, however, a real reason for hope: humanities scholars will be able to try it out for themselves and with a bit of luck, we will have a broader view on its usefulness for cultural analysis in a couple of month.
When it comes to scrutinizing companies for their actions and policies concerning control over information, privacy issues, and market dominance in areas related to public debate, large media conglomerates have been the traditional objects of analysis. More recently, Internet giants such as Google and Facebook have been critically examined and when the hype levels off, Twitter will probably be the next on the list. Malcolm Gladwell’s recent piece in The New Yorker may very well be an indicator of things to come.
Whether the issues related to “social media” are important or not, I have the feeling that the debate overshadows questions and problem fields that may in fact be much more important. The most obvious case, in my view, is the debate on privacy on Facebook. While the matter is not irrelevant, I think that e.g. present and future state-run information systems such as the french EDVIGE, a central police database that assembles all kinds of personal information concerning select persons “of interest”, have been overshadowed by debate on whether your employer can see the pictures that document your drinking binges after somebody (you?) put them on the ‘Book. There is a certain disequilibrium in how Internet researchers and critics distribute their attention that has allowed all kinds of things to pass below the radar. But there is one event that has really shook me up recently, both because of its importance and the lack of outcry it garnered, at least in my echo chamber: the acquisition of the Reuters group by the Thomson corporation in 2008 and the creation of Thomson Reuters, an information giant second to none.

Thomson Reuters market divisions
I have stumbled upon Thomson Reuters a couple of times over the last years: first, when I researched the history of citation indexing, I learned that Thomson Scientific had bought the Institute of Scientific Information (and their Web of Science citation index megabase from which things like the notorious Impact Factor are calculated) in 1992; then again when I noticed that the ClearForest API for term extraction had be renamed, remodeled, and rebranded as OpenCalais after Reuters bought the company in 2007; finally, last year, when I noticed that the Reuters video platform appeared more and more often in articles and links. When I finally started to look a little closer (NYSE:TRI) I was astounded to find a company with a market cap of $31B, annual revenues of $13B, and 55K+ employees all over the world. Yes, this is no Apple big, but still very, very big for a company that sells information.
I knew Reuters from my studies in communication science as the world’s biggest news agency (with roughly one and a half competitors: Associated Press and Agence France Presse) but I had never consciously registered the Thomson company – a Canadian Family business that went from the media (owning the London Times at one point) to publishing before transforming itself in a rather risky move into a digital information broker for all kinds of special fields (legal, health, finance, etc.). Reuters was a perfect match and I really wonder how that merger went through without too much hassle from the different regulatory bodies. Even more so when I found out that Reuters actually had devised a very spicy regulatory clause when it made its IPO in 1984: to avoid control over such a central source of information, no single shareholder would be allowed to hold more than 15% of the companies stocks. Apparently, that clause was enacted at least once when Murdoch’s News Corporation (already holding 15%) bought a competitor that also owned a piece of Reuters and consequently had to shed stock to stay below the threshold. The merger effectively brought the new Reuters Thomson under full control (53%) of The Woodbridge Company, a private holding that represents the Thomson family.
Such control over a news agency (and the many more specialized services that are part of the giant’s portfolio) should give us pause in the best of times when media companies are swimming in resources, are able to pay good money for good journalism, and keep their own network of correspondents. But recent years have seen nothing but cost cutting in journalism, which has led to an even greater reliance on news agencies. I wager that Google News would work a lot less well if people actually started to write their own copy instead of remodeling Reuters’ and AP send outs.
But despite these rather traditional – but nonetheless crucial – concerns over media ownership and control, there is a second point that is somewhat closer to my area of expertise. I have recently been thinking a lot about how to best phrase criticism of the assumption that digital networks necessarily lead to decentralization. Thomson Reuters – but also other information giants such as Google and Facebook – is a great example for how digital technologies can lead to quite impressive cost reductions for economies of scale and, consequently, market concentration. These arguments should be taken into account:
- While the barriers of entry to the Internet are really low (you can have your own blog in minutes), scaling up to millions of visitors is a real challenge. Building your own datacenter is a real bump in the learning curve and to get over it, you need to make certain investments. But once you pass that bump, scaling suddenly becomes cheaper again because you have the knowledge ressources and experience that can now be applied to make the datacenter grow. One of Google’s strengths lies in this area and this immensely facilitates branching out into new information ventures. The same goes for Thomson Reuters: they master platform technology and distribution technologies for all kinds of contents and they can build on that mastery to add new things to serve information to a globalized planet. To use the language of the long tail: there may be more special interest information that can find an audience with shelve space becoming effectively unlimited; but there is also no longer a need for more than one shelve.
- The same goes for a more elusive matter: the mastery of information. The database techniques and indexing tools we use to store information – as well as the search and data-mining algorithms – can be very easily transported from one domain to the next. While it may be (very) difficult to create useful search tools for medical information, once you have built them it is rather easy to adapt these tools to, let’s say the legal domain. Again, this is what makes Google strong: basic search technology can be applied to advertising, books, mail, product prices, and even video if you can do automatic transcription. With the acquisition of ClearForest, Thomson Reuters has class-leading in-house data-mining and this is not something you can get by simply posting a couple of job ads in the local newspaper. Data-mining is extremely useful in areas where fast decision-making is crucial but also when it comes to building powerful search tools. Again, these techniques can be applied to any number of fields and once you have the basics right you can just add new domains with very little cost.
These two points go a far way in explaining why the Internet has seen the lightning fast emergence of network giants over the last couple of years. I really don’t want to postulate yet another “law” of the Net but I believe that there is something to this idea of the bump: it’s easy to have a basic presence on the Web but it’s hard to scale up to a large audience and to use advanced computational techniques; but one you pass the bump, the economies of scale kick in and from there it seems like there are no barriers to growth. The Thomsons have certainly made that bet when they acquired Reuters and so far, it seems to work out quite nicely for them.
I hope we can find a means to extend critique from questions of ownership into the heart of the (informational) beast and come up with better ways to understand how the still ongoing shift to exclusively digital information affords new means of handling and exploiting that information – with organizational, economic, and political consequences. While that work is starting to take shape for consumer companies like Google that are in the spotlight, there is surprisingly little on invisible network giants like Thomson Reuters that cater mostly to professional clients.
This blogpost is somewhat of an experiment that I hope will turn into a series. I have started to work seriously on a book that will suggest a somewhat different take on understanding computing and particularly contemporary software deployed on the Internet. A large part of that work consists of historical analysis and in this context I am (re)reading many of the seminal papers of the information and computer sciences. What is striking about these texts is not only their content but their far-reaching influence on the landscape of technological concepts and, often enough, on the actual technological developments that followed. Writing software today is in most cases an articulation that takes place in an extremely dense space of established languages, APIs, frameworks, and libraries but also of concepts, methodologies, best practices, tacit assumptions, strategies, and community rules. There is so much “old” in every “new” but many concepts have become so pervasive, so dominant that we no longer see them as the particularities they in fact are. Being canonical, they become second nature. But many of these path-defining moments can be retraced and given the pervasiveness of computers today, an archeology of computing is, in a way, an archeology of our culture.
One of the ways to do such an archeology may simply consist in trying to read seminal computer and information science papers sideways, not (only) as technological proposals, but as political and cultural projects that combine a (most often critical) analysis of a status quo with a prescriptive take on how a more ideal setting could/should look like. Technology is, in that sense, a way of relating to society, a means of contributing that is political in a very different way than the traditional arenas of governance and debate. What I would like to suggest is that this aspect of technological writing (science papers but also reports, RFCs, norms, proposals, documentation, etc.) is by far not examined enough, particularly when it comes to techniques that are related to software. Our view of technology is still very much shaped by the physical machine – the box, the screen, the keyboard – perhaps also because these physical parts are closer to our bodies, more visible and easier to integrate into the cognitive practices of a culture that, paradoxically, is able to produce extremely sophisticated mechanisms while being quite inept when it comes to understanding the role technical objects play in constituting its very fabric.
In my view, the central mistake is to assimilate technology to techné and be done with it. Perhaps I am wrong, but I cannot shake the feeling that very few scholars in the humanities and social sciences are prepared to accord to technological creation the same depth, complexity, variety, the same imbrication in society, the same amount of “humanity” than literature or artistic creation in general. This unwillingness to really engage technology beyond the surface leads to the familiar reflex-like reactions, both positive and negative, that seem to dominate public debates on “hot” topics like social networking, privacy on the Internet, or computer games.
So what I am looking for is a different way of understanding technology that subscribes neither to an engineering perspective concerned with function nor to a purely “culturalist” analysis that sees only imaginaries, symbols, and metaphors, thereby risking to loose the machine in the machine. So, today, first try and why not start with a big one.
In 1970, Edgar F. Codd, a British computer scientist who moved to the US in the 1940s, published one of the most influential papers in the history of computer science, A Relational Model of Data for Large Shared Data Banks (available here, doi:10.1145/362384.362685), in which he proposed a concept for the construction of database systems built around the central idea of separating the logical organization of information from the way it is stored on a physical storage medium. While the usefulness of such a separation may seem very obvious from today’s viewpoint, Codd’s paper stirred a virulent debate and his employer, IBM, was quite reluctant when it came to turning the proposal into a product (it took eight years for the first relational database system to make it to the market). When discussing Codd’s work, we should be very suspicious of the popular narratives of technological development as a series of inventions, or worse, ideas. To separate logical organization from physical storage had been a common practice in libraries for a long time: the library catalogue, in combination with some basic shelf logistics, allows for very different ways of recording books – alphabetically, by subject, and so on. But technologies are not simply ideas; Gene Roddenberry did not invent beaming. As science and technology studies have shown many times, a successful scientific “discovery” or a technological “invention” is somewhat of a “perfect storm”: many pieces have to fall into place, many different actors have to be mobilized, and most often there is talking, writing, demonstrating, debating, and a whole lot of fuzz. As computer history shows, having an idea (Babbage) or even building a functioning machine (Zuse) may simply not be enough to establish a technology. Since the industrial revolution, technologies are increasingly often systems that require logistics, markets, organizational reform, or an installed user base. In our case, the really interesting thing is not necessarily the abstract idea for what has become today’s omnipresent relational database, but the way Codd builds an idea into a technological concept, as an argument as well as a potential system. To start, let’s quote the abstract in full:
Future users of large data banks must be protected from having to know how the data is organized in the machine (the internal representation). A prompting service which supplies such information is not a satisfactory solution. Activities of users at terminals and most application programs should remain unaffected when the internal representation of data is changed and even when some aspects of the external representation are changed. Changes in data representation will often be needed as a result of changes in query, update, and report traffic and natural growth in the types of stored information.
Existing noninferential, formatted data systems provide users with tree-structured files or slightly more general network models of the data. In Section 1, inadequacies of these models are discussed. A model based on n-ary relations, a normal form for data base relations, and the concept of a universal data sublanguage are introduced. In Section 2, certain operations on relations (other than logical inference) are discussed and applied to the problems of redundancy and consistency in the user’s model. (p. 377)
First of all, who are these users that have to be “protected”? In 1970, this is obviously not (yet) the manager sitting in front of a screen and keyboard but rather the application programmer that will implement the “query, update, and report” functions every larger organizations rely on for management. These users/programmers had been forced to make changes in storage structures whenever requirements changed in a significant way. This was not just an onerous task but also a source of potentially crippling problems as every adaptation risked breaking existing applications. Without explicit reference, Codd’s work is directly related to what has become to be known as the “software crisis” that lead to the emergence of software engineering. The separation of systems into black-boxed modules that communicated via well-specified interfaces was one of the solutions put forward to counter the explosion of complexity that followed the introduction of computers into large-scale, real-world (business) organizations. Seen in this light, the relational model and the concept of “data independence” (p. 377) is an extremely powerful agent for the division of labor that cleanly separates the engineering of a database system from the specification of data structures, adding to the ground work for the concept of end-user software that we know today.
So what is Codd’s proposal? For a reader trained in the humanities trying to read a paper like the one in question (even the first half, which does not use any formal notation), adaptions to the habitual reading style have to be made to get something useful out of it. Much like mathematics, computer science deploys language quite differently than the humanities (except for analytical philosophy): language, here, is not (only) narrative and argumentative, it aims a building a demonstration, which is most certainly a rhetorical form, but a very formal one that follows a convention consisting of laying out a space of thinking through a series of very precise definitions, which often attribute quite specific significations to words taken from everyday language. Miss one of these definitions and the whole pyramid crumbles. In Codd’s case, the basic building block is the concept of relation (taken from mathemataical set theory, like most reasoning about databases), which designates a basic form for structuring data where every abstract entity is composed of a series of attributes. This data structure can be “filled” with entries (rows). If you’re familiar with SQL (today’s standard query language, derivative of Codd’s work), relation (or rather relationship, the unordered version of relation in Codd’s paper; nowadays, relation is used for Codd’s relationship and I’ll follow that convention) is simply the structure of a table. In practice, Codd suggest to build databases that represent all data in a from that looks like this:
students: name email major
Jack jack@email.com history
Mary mary@email.com science
Here, students is a relation composed of three attributes (name, email, number). Jack is a row (entry), Mary is another one. What was new in this definition is obviously not the notion of the table, but rather the idea to define a relation as a purely abstract and unordered structure, a logical construct that did not specify in any way how it was to be stored on a physical medium. An important indicator for this decoupling is Codd’s comment that “the ordering of rows is immaterial” (p. 379). Without stating it explicitly, Codd shifts the construction of order from the storage to the query. More on this later.
The second key concept is the notion of primary key and its corollary, the foreign key. Let’s add a primary key to our table:
students: key name email major
1 Jack jack@email.com history
2 Mary mary@email.com science
The primary key is a way of addressing a row of data unambiguously (student #1 is Jack and no other student, keys have to be unique). The idea of a foreign key means to simply use a primary key in another table. Instead of doubling information (which may lead to all kinds of update problems as well as storage overhead), we’re simply “pointing” from one table to another. Take the relation (table) “grades”:
grades: student.id english history geography
1 C C C
2 B B B
In this case, students.id (relation.attribute is the notation we still use today) is the foreign key linking to the primary key of our “students” relation. In practice this means that Jack had all Cs and Mary all Bs in the three classes they took. Codd shows that using this concept of primary/foreign key, very complex organizations of data can be produced while keeping the basic principles very simple. While both of the dominant models of the time, the tree and network models, were based on data hierarchies (that had to be rebuilt if informational practices changed), the relational model is much more flexible.
To put things into perspective: most of the world’s structured data is currently organized according to this basic form. I would guess that despite the current NoSQL hype (companies like Google and Facebook use even simpler and highly customized data structures for ultra-high speed access) more than 90% of all Web applications have a database backend based on one of the many implementations of the relational model, e.g. Oracle, MS SQL Server, MySQL, PostgreSQL, to name just a few. But data organization is only the first half of the proposal.
The next step in Codd’s paper is to reflect on a language that would allow for data retrieval and manipulation by addressing the logical organization of the data rather than its physical storage. Rather than specifying the physical location of the data, saying “I want the entries from address 0x00000 to address 0xfffff” (and we would have to know these addresses beforehand!), we could simply ask for all the entries in the table students. Remember that above, I indicated that Codd declared entry order as “immaterial”? This is because the ordering of data is no longer (merely) a property of the archive. Ordering is done in the language we use to get the data: “I want all the students, sorted alphabetically by name” (SQL: SELECT * FROM students ORDER BY name). The data structure has of course be prepared for the kind of queries we will want to make, but in our example, I could group my list by major, sort it by email, or, by “joining” our two tables, order by grade average. More elaborate queries would allow me to select the 25% percent students with the best grade average or to plot the grade evolution over the years if I have that data.
A data retrieval and manipulation language would have to do more than just query and this quote summarizes the requirements:
A set so specified may be fetched for query purposes only, or it may be held for possible changes. Insertions take the form of adding new elements to declared relations without regard to any ordering that may be present in their machine representation. Deletions which are effective for the community (as opposed to the individual user or sub- communities) take the form of removing elements from declared relations. (p. 382)
These are the four building blocks of every database system I have worked with (again using SQL): SELECT (query a database using different parameters for searching and ordering, e.g. get all students with a certain grade average), INSERT (insert new data into a table, e.g. add a new student into students), UPDATE (change data, e.g. change a student’s grade after accepting a bribe), DELETE (erase date, e.g. expel a student for offering you a bribe). Such a language – Codd will propose the Alpha language in the 1970s but IBMs SQL (structured query language; Larry Ellison of Oracle actually was the first to bring a SQL based product to the market and consequently became one of the richest people on the planet) largely won out – would again “protect” the user from having to interact with anything but the data organization specified in the terms of the relational model.
In the rest of the paper, Codd tackles a series of problems that could arise in the implementation of actual systems (and what we would call a “storage engine” today) based on the relational model, but this part is less interesting for my purposes.
I would like, however, to propose a couple of comments that may help putting things into a larger perspective:
1) The central critique of Codd’s proposals came from programmers and engineers that abhorred the loss of control (an potentially performance) over the actual organization of data storage on the physical medium and the dangers such a black-boxing may pose to data integrity in the case of dysfunction or accident. But in the 1980s the demands for more flexibility and cost control won the day, driven by lower hardware costs and better techniques for securing data. This evolution towards layering, modularity, and a general “abstraction” from the hardware has happened in all fields of computing and, indeed, the loss of control and visibility is most often the prime concern. In a sense, software has followed a similar trajectory as social organization, from community to society (and back, whenever there is a new frontier to homestead), that is from small-scale teams and organizations to the large-scale efforts of companies like Microsoft or Oracle. Abstraction techniques like Codd’s played a central role here as enablers of division of labor. It also permitted – and this is crucial – a much tighter integration between management processes and information technology. The moment information structures are “liberated” from questions of physical storage, they can be implemented in flexible, end-user friendly software packages, which makes it possible for management to interact much more directly with data. The rise of Business Intelligence and Decision Support Systems would have been much less spectacular without the relational model turning “information” into the malleable material it has become.
2) While I am of course tempted to write something like “The decoupling of the logical structure of data from physical storage and the immense power and flexibility afforded by query languages have led to the emergence of late-modern network economies.”, this would be too quick and easy. The relational database, the powerful query languages, and the business control and intelligence functions they enable are certainly a central part of the informational infrastructure that supports contemporary economic organization. Data, once collected, can be interrogated from every possible angle and automatic reporting (which is no more than a series of very elaborate SQL queries over a large number of tables) has introduced incredible speed into business processes, while keeping up an illusion of control. Illusion, because just like any formal model of reality, data and query models are necessarily reductionist. At the same time, databases are themselves part of a much longer trend in management that started with systems management in the late 19th century. We’re snowballing from one information age to the next and technologies like the relational model are as much enablers as results, causes and effects.
3) The relational database is part of a much larger transformation in how documents, information, and knowledge are handled. From the library catalog to documentation centers and further on to data banks, information retrieval, and data mining, we see a steady growth in the attention being payed to the logistics, organization, and “exploitation” of an always faster growing mountain of texts, images, sounds, and so forth. The relational model not only helps with classic tasks such as storage and retrieval, it shares in the birth of the what could be called the “automated production of knowledge”, i.e. the creation of new information from cross-referencing, comparing, statistically examining, synthesizing, and representing large quantities of information. Whether these automated processes (think reporting, data mining, etc.) produce “real” knowledge is a rather stale question; it is much more important to emphasize how businesses and other organizations have come to depend on these tools for everyday management and decision-making. Query languages built on Codd’s proposal constitute the foundation for these developments.
There would be much more to say about Codd’s work and the relational database but I want to close by going back to the initial question about reading computer science from a humanities perspective. A classic analysis of language and use of metaphors would probably have proceeded quite differently and would have homed in on things like the “protection” of users or citations such as this footnote:
Naturally, as with any data put into and retrieved from a computer system, the user will normally make far more effective use of the data if he is aware of its meaning. (p. 380)
Imaginaries are indeed important aspects of an archeology of computing but even in written form, computer science is, in a way, always looking elsewhere, beyond the text, and Codd points to this “elsewhere” in his last paragraph:
Nevertheless, the material presented should be adequate for experienced systems programmers to visualize several approaches. (p. 387)
What Codd asks the reader to visualize is the laboratory of computer science, the site where things come together, the working system. While the discursive aspects are certainly important, I feel that function is central to the poetics of the technical sciences and if we want to understand their cultural significance we have to read them both as texts and as functional blueprints.