Category Archives: critique
EDIT (24/08/2019): Netvizz is no longer publicly accessible and will very probably not come back in the future.
EDIT (06/08/2019): This morning, I received notification that Netvizz will lose access to the “Page Public Content Access” permission on September 4, 2019. This means that most of the app will very probably stop working on that date.
For the last ten years, I have been developing a Facebook app for researchers called Netvizz. It started as part of a class on advanced web programming I was teaching at the département hypermédia and morphed quite a bit over the years, often in response to API changes. After losing the ability to generate graph files for friendships, it kind of stabilized around analysis for Facebook Pages and – to a lesser degree – Groups. If you check the almost 300 scholarly papers that cited the accompanying publication – and the many more that did not – you get a good idea what outputs were used for.
When the Cambridge Analytica scandal hit earlier this year, I expected trouble. Although the data doors that allowed CA to gather the data they did were closed in 2015 already, Facebook had to react. A new API version and stricter terms were introduced and, most importantly, all apps would again have to submit to a review. Netvizz was also part of a group of “suspicious applications” that received particular scrutiny concerning their past activities (here is the questionnaire I was asked to fill out). This certainly makes sense, since I could have easily created a treasure trove of data by storing all the data requested through the app.
Looking forward, however, was the new permission system and the connected app review. In order to continue to retrieve data for Pages, the new Page Public Content Access permission is needed. As always, the use cases for getting this permission are rather vague and make no room whatsoever for academic research. Since many researchers and students are relying on Netvizz, I wanted to give the app review a shot.
Such app reviews are not some interactive dialogue with a human operator, but a bunch of form fields and the request to record a screencast that explains how permissions are used. This then normally yields a canned response, not some explanation that actually reflects the submitted app. There is no email address, no appeal process, no “relationship” other than the pre-formatted interface and some pre-formatted answer.
After an initial refusal because “permissions data must be visibly used within your app”, which I think means that you cannot just provide data download, I added a bunch of in-app visualization modules and tried again. After two more attempts, I ended up with a one sentence explanation in the form of a “note from your reviewer”: 
While I am not sure what this actually means in practice, it seems clear that the single-page, data-download focused approach Netvizz has been taking is not part of what Facebook wants on its platform in the future. There is maybe room for some widget-driven page comparator and maybe there is a way to sneak out some data that way, but it would go too far to try and build something like this in this structurally opaque and unhelpful environment. So this is where it ends, at least for the moment. Netvizz still functions as I am writing this (try out the new page like visualization module, which allows you to interactively crawl into the network of liked pages, it’s kind of cool) and may very well continue to live a zombie existence in the future – I do not know and have no means to find out.
After tweeting about this process, I not only received a lot of support, but also suggestions to launch some kind of campaign, possibly on the basis of the academic outcomes Netvizz has helped with or enabled. Maybe such an attempt could work, but I personally doubt it since academic research is set to be funneled into new institutional forms that offer more control than API-based data access. Maybe Axel Bruns’ open letter initiative can develop into something like this. I surely hope it does, but for myself it is time to take a break.
Running after too many API changes and jumping through too many bureaucratic hoops over the last three years has made it clear how unsustainable my attempts to provide a tool like Netvizz have really been. Since all my technical work is done in my spare time (I receive no teaching discharge or other compensation from my university) it is simply not possible any more to navigate an environment that has changed so much from the happy go lucky mashup days that started this process. I enjoy programming like few other things in life and even decided to take my university job part time – losing more than half of my salary in the process – to be able to keep doing it, but the increasing hostility toward independent research is creating demands that can only be tackled through more sustainable institutional forms. If any successful resistance to these developments can be mobilized, it will require substantial support from organizations capable of investing resources that may not lead to immediate deliverables or quantifiable publications. At least in my immediate environment, I do not see such forms emerge.
All of this may change again, but for the moment I will take a step back from Netvizz to focus on my more conceptual interests. Facebook will continue to be scrutinized in different forms and through different methods, but the idea that independent research of a 2+ billion user platform just got a lot harder should make us at least a little uneasy.
Social media platforms have become really huge. They have very large numbers of users, who share very large numbers of messages, images, videos, and so forth. They have a whole lot of spare cash, either from advertising revenue or from IPOs. They have not only become an intrinsic part of interpersonal communication and of the way we inform ourselves, but much of what news organizations report nowadays seems to be about who tweets what to whom with what effect. The controversy around how Facebook editorializes the newsfeed and trending topics is only the latest indicator for the enormous imprint on the circulation of information and ideas the company now has. The European Commission has recently launched a public consultation on the role of platforms, in reaction to two reports by the German and French governments on the topic.
One of the key terms in all of this is “transparency”. Often this concerns moments of decision-making such as ranking, filtering, pricing, suggesting, and so forth. And often the debate focuses on the role of algorithms vs moments of human discretion (the opposition is problematic in many ways, but that’s another topic). Demands for transparency then focus on “opening the black box” and Facebook’s recently published guidelines fit into this framework. But there is another aspect to transparency that is less often evoked, which concerns the question “what is actually going on in these platforms?”. This goes beyond the question of algorithms to include the very communicational makeup of these systems (interfaces, functions, etc.) and, even more importantly, the concrete results of large masses of users actually integrating these technical elements into their practices. Transparency, in that sense, is not simply concerned with knowledge about the system’s design, but with the ways users and technical infrastructure form an integrated whole that produces specific outcomes in terms of circulation of information and ideas. One way to understand this integrated whole a little better is empirical research, whether it happens on the micro level in the form of ethnography, on the meso level around specific issues, or on the macro level in the form of large statistical aggregations. Empirical research is, ultimately, the only way to understand what the editorializing (which includes the full design of the service, not just filtering) of Facebook and other companies actually means in terms of outcomes or effects.
But empirical research on large online platforms is getting more and more difficult. Last year, Facebook removed a number of functions from their API, and research applications like Netvizz lost a part of their capacity to produce transparency by giving researchers the means to do (a certain kind of data-driven) empirical research. The latest case is Instagram. Already a year ago, the company announced that every application would have to go through a permission review to be allowed to continue. My own Instagram Hashtag Explorer (which I renamed to Visual Tagnet Explorer – VTE – to conform to the app guidelines which prohibit the use of the company name) has been relying on API data to help researchers understand how people use Instagram to produce visual and textual accounts of issues, events, places, companies, and so forth. After submitting the app for review, I today received notification that the application was denied. A detailed description of the tool and a screencast that attempted to connect the tool – in not totally absurd ways I think – to the “accepted use cases” were not good enough to yield any more commentary than this:
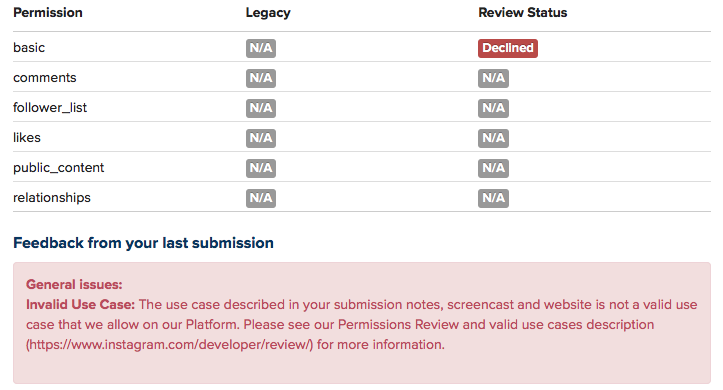
Now, we can lament about lost programming time (it wasn’t much fortunately) and research projects that will run into trouble, but the real problem, I think, connects to the question of transparency as I framed it above. Sure, a little script would never have solved the problem how to understand platform dynamics, but it was a little step on the ladder. There are certainly other means to do research and even data-driven research will be possible through scraping. But I wonder how far ethnographic studies, for example, are able to address questions concerning macro effects. And I wonder how sustainable and scalable scraping is. Sure, we can play the cat and mouse game with automatic bot detection and evolving interfaces, but is this going to produce the large window on these platforms we need to really understand them in terms of their effects on publicness? Maybe I’ll make some changes to VTE and submit it again, even though I have basically no feedback to go on. Maybe it will pass. But the larger problem will remain.
What is needed, I think, is something different. Yes, data retrieval, even by academic researchers, raises concerns about privacy. But privacy is not the only legitimate political aspiration, here. What, indeed, about publicness? What about the need to know about stuff in order to make democratic decisions? How to even begin to think about regulation if real outcomes are getting more and more difficult to assess? This is why I want to iterate an argument that I already tried to make during the EC’s public consultation: we need a legal framework to guarantee at least some access to API data, at least for some people. It is certainly nice that companies start research collaborations, but these fit of course into a sanitized view on their services. We therefore need, I think, something that is able to express the public’s legitimate interest to know “what’s going on” and access to API data is, in my view, a more promising avenue than the forms of purely technical or operational transparency that are often discussed. Fair use principles, for example concerning copyright, exist in academia because there is a belief that research that is not beholden to corporate interest performs a function in public life that is worth protecting. Can we imagine something similar with API data? A legally protected means to do research into these platforms? To find a compromise between privacy and publicness, we would have to find a way to distinguish between “disinterested” research and other applications. But technically, everything is in place. The APIs are there, even if they are closing down after their utility for growing the ecosystem has expired and selling data to analytics companies is becoming a revenue stream. The tools are in place and the researchers are starting to understand how to use them in useful ways. Compared to the daunting legal battles around antitrust measures, it’s almost banal to make this a reality.
Even if this idea proves to be a pipe dream, I think that we have to widen the debate around the values to take into account when criticizing the role of platforms in public life. Privacy is important, but public understanding of outcomes is as well.
In 1961, Information Pioneer Mortimer Taube (famous for popularizing mechanized coordinate indexing) wrote a book called Computers and Common Sense. The Myth of Thinking Machines. (Columbia University Press). Here is a quote that reminded me a lot of Philip Agre’s Computation and Human Experience:
About a year ago the author was privileged to sit one evening with a group of data processing experts who were attending an institute in Poughkeepsie. Conversation turned to learning-machines. Most of those present had no doubts that machines capable of learning would soon be built. When questions were posed concerning the nature of learning in men and machines and whether or not learning in one was similar or identical to learning in the other, a curious fact emerged. There was considerable agreement among those present concerning the nature of learning in machines, but wide disagreement concerning the nature of human learning. There was agreement that the term “learning,” when applied to human behavior, was vague and ill-defined in spite of the efforts of psychologists to evolve theories of learning. Out of all this a curious consensus emerged. Just because “learning” had no definite meaning when used to describe human behavior and did have a definite meaning when used to describe the activity of a machine, it seemed reasonable to accept the definition which applied to machines and to extend the same definition to cover human action. In other words, man-machine identity is achieved not by attributing human attributes to the machine, but by attributing mechanical limitations to man. (p.42)
One of the reasons I started to develop the netvizz application, was to get better insights into how Facebook envisions exchange of data and functionality with third party developers. From the beginning, I was quite amazed how much data a third-party app could actually get from the platform – not only about the users that actually install an app, but also about their friends and the groups they are members of. I hope to provide a systematic account of what I’ve learned at some point in the future. But today, I want to discuss a particular element in some more detail, the “read_stream” permission.
To introduce the matter, a couple of points concerning the Facebook APIs as such: every application written by a third-party developer requires a logged in user and this user defines the “scope” of data access the running instance of the application can get – remember that applications are generally used by many users, so the data gleaned from individual scopes can be combined. Applications have to explicitly ask for permission to access certain items and Facebook provides extensive documentation on the permission system, the profile properties, and a set of extended permissions. Users are asked to grant these permissions when they first start an app. This is the permission dialogue for netvizz:

Netvizz currently asks for the following permissions: user_status, user_groups, friends_likes, user_likes, and read_stream. When installing, you cannot refuse individual elements that are not considered “extended permissions”, only decide to not use the app at all. The user_status is actually superfluous and will be removed in the next iteration. The user_groups permission is needed to access group data and both _likes permissions are used for netvizz’ like network functionality.
Now, working on a couple of new features over the last months, I started to get more interested in posts because they have probably become the closest thing to a “carrier of publicness” on the Facebook platform. I was quite amazed how easy it was to extract large numbers of users and (some) of their data from pages – both likes and comments users make on post on or by pages are in principle up for grabs. When doing some housekeeping recently, I noticed that some of the “engagement” metrics netvizz had provided for users’ friends in earlier versions were either broken or outdated and I decided to simply count the number of likes and posts friends make to replace the older metrics. I expected to only be able to read likes – through the friends_likes permission – and public posts. This was indeed true: in the beginning, all I got were public posts. Because I could get much more data through the Graph API Explorer, a developer sandbox that asks for all permissions by default (which can be changed, a great way to explore the permission structure), I discovered the read_stream permission.
The read_stream permission is presented by Facebook in the following way: “Provides access to all the posts in the user’s News Feed and enables your application to perform searches against the user’s News Feed.” It is a so-called “extended permission”, the developer doc noting that “Extended Permissions give access to more sensitive info and the ability to publish and delete data”. And, indeed, when asking for read_stream in netvizz, I suddenly got access to many more posts made by my friends, mostly going from “none” to “a lot”. From what I could gather after some random testing was that I basically got access to all of the activities from my friends that would show up in my newsfeed, without the “top stories” filter. Because many things have the status of “post”, I could get a rather detailed (and timestamped) account of what my friends are doing on the platform. You can check out your own “posts” feed by following this link into the Graph API Explorer. Because comments and likes by users who you are not friends with on posts by somebody you are friends with also show up in your news feed, the read_stream permission allows to capture their activity as well. Facebook seems to be aware of this: because read_stream is an extended permission it gets its own permission dialogue and can actually be skipped:

This is a good thing, but the wording seems a bit sparse: “Posts in your newsfeed” actually translates to “a minute account of your friends’ activities”. Granted, buried in the privacy settings is an option that allows us to modify more generally what information we share with the apps other people use, and these are the default settings:

It’s the “Activities, interests, things I like” option that allows the read_stream permission to work its magic. The people I am friends with on the platform are generally a rather privacy conscious bunch, but I could get the posts from most of them.
This is not a privacy scandal of any sort, measures are in place, but one can still make a couple of points:
- Apps as means for data capture are clearly not discussed enough. For serious data collection, however, going through the API is clearly the way to go and we need to pay more attention to this.
- Again and again: defaults matter. As seen above, the data available to apps used by friends is quite extensive with default settings.
- Again and again: language matters. The read_stream permission dialogue is certainly not explicit enough. Also: why is “app privacy” not in the privacy tab here?
- When we log into a third party site with our Facebook login, we are basically running an app. May be worth pondering what data we are shipping over.
Exploring APIs as important actors in the privacy debate and beyond is crucial. It’s often complicated work, though, and I hope that the developer community can help with that work a bit. It would be highly useful, I think.
Yesterday, Google introduced a new feature, which represents a substantial extension to how their search engine presents information and marks a significant departure from some of the principles that have underpinned their conceptual and technological approach since 1998. The “knowledge graph” basically adds a layer to the search engine that is based on formal knowledge modelling rather than word statistics (relevance measures) and link analysis (authority measures). As the title of the post on Google’s search blog aptly points out, the new features work by searching “things not strings”, because what they call the knowledge graph is simply a – very large – ontology, a formal description of objects in the world. Unfortunately, the roll-out is progressive and I have not yet been able to access the new features, but the descriptions, pictures, and video paint a rather clear picture of what product manager Johanna Wright calls the move “from an information engine to a knowledge engine”. In terms of the DIKW model (Data-Information-Knowledge-Wisdom), the new feature proposes to move up a layer by adding a box of factual information on a recognized object (the examples Google uses are the Taj Mahal, Marie Curie, Matt Groening, etc.) next to the search results. From the presentation, we can gather that the 500 million objects already referenced will include a large variety of things, such as movies, events, organizations, ideas, and so on.

This is really a very significant extension to the current logic and although we’ll need more time to try things out and get a better understanding of what this actually means, there are a couple of things that we can already single out:
- On a feature level, the fact box brings Google closer to “knowledge engines” such as Wolfram Alpha and as we learn from the explanatory video, this explicitly includes semantic or computational queries, such as “how many women won the Nobel Prize?” type of questions.
- If we consider Wikipedia to be a similar “description layer”, the fact box can also be seen as a competitor to everybody’s favorite encyclopedia, which is a further step into the direction of bringing information directly to the surface of the results page instead of simply referring to a location. This means that users do not have to leave the Google garden to find a quick answer. It will be interesting to see whether this will actually show up in Wikipedia traffic stats.
- The introduction of an ontology layer is a significant departure from the largely statistical and graph theoretical methods favored by Google in the past. While features based on knowledge modelling have proliferated around the margins (e.g. in Google Maps and Local Search), the company is now bringing them to the center stage. From what I understand, the selection of “facts” to display will be largely driven by user statistics but the facts themselves come from places like Freebase, which Google bought in 2010. While large scale ontologies were prohibitive in the past, a combination of the availability of crowd-sourced databases (Wikipedia, etc.), the open data movement, better knowledge extraction mechanisms, and simply the resources to hire people to do manual repairs has apparently made them a viable option for a company of Google’s size.
- Competing with the dominant search engine has just become a lot harder (again). If users like the new feature, the threshold for market entry moves up because this is not a trivial technical gimmick that can be easily replicated.
- The knowledge graph will most certainly spread out into many other services (it’s already implemented in the new Google Docs research bar), further boosting the company’s economies of scale and enhancing cross-navigation between the different services.
- If the fact box – and the features that may follow – becomes a pervasive and popular feature, Google’s participation in making information and knowledge accessible, in defining its shape, scope, and relevance, will be further extended. This is a reason to worry a bit more, not because the Google tools as such are a danger, but simply because of the levels of institutional and economic concentration the Internet has enabled. The company has become what Michel Callon calls an “obligatory passage point” in our relation to the Web and beyond; the knowledge graph has the potential to exacerbate the situation even further.
This is a development that looks like another element in the war for dominance on the Web that is currently fought at a frenetic pace. Since the introduction of actions into Facebook’s social graph, it has become clear that approaches based on ontologies and concept modelling will play an increasing role in this. In a world mediated by screens, the technological control of meaning – the one true metamedium – is the new battleground. I guess that this is not what Berners-Lee had in mind for the Semantic Web…
This preprint of a paper I have written about a year and a half ago, entitled Institutionalizing without Institutions? Web 2.0 and the Conundrum of Democracy, is the direct result of what I experienced as a major cultural destabilization. Born in Austria, living in France (and soon the Netherlands), and working in a field that has a strong connection with American culture and scholarship, I had the feeling that debates about the political potential of the Internet were strongly structured along national lines. I called this moral preprocessing.
This paper, which will appear in an anthology on Internet governance later this year, is my attempt to argue that it is not only technology which poses serious challenges, but rather the elusive and difficult concept of democracy. My impression was – and still is – that the latter term is too often used too easily and without enough attention paid to the fundamental contradictions and tensions that characterize this concept.
Instead of asking whether or not the Internet is a force of democratization, I wanted to show that this term, democratization, is complicated, puzzling, and full of conflict: a conundrum.
Published as: B. Rieder (2012). Institutionalizing without institutions? Web 2.0 and the conundrum of democracy. In F. Massit-Folléa, C. Méadel & L. Monnoyer-Smith (Eds.), Normative experience in internet politics (Collection Sciences sociales) (pp. 157-186). Paris: Transvalor-Presses des Mines.
Over the last couple of weeks, things have heated up considerably for Google – on the mobile side with the start of a patent war, but also in the search area, the core of the company’s business. Led by Senator Mike Lee (a Utah Republican), the US Senate’s Antitrust Subcommittee has started to probe into certain aspects of Google’s ranking mechanisms and potential cases of abuse and manipulation.
In a hearing on Wednesday, Lee confronted Eric Schmidt with accusations of tampering with results and the evidence the Senator presented was in fact very interesting because it raises the question of how to show or even prove that a highly complex algorithmic procedure “has been tampered with”. As you can see in this video, a scatter-plot from an “independent study” that compares the search ranking for three price comparison sites (Nextag, Pricegrabber, and Shopper) with Google Price Search using 650 shopping related queries. What we can see on the graph is that while there is considerable variation in ranking for the competitors (a site shows up first for one query and way down for another), Google’s site seems to consistently stick to place three. Lee makes this astounding difference the core of his argument and directly asks Schmidt: “These results are in fact the result of the same algorithm as the rankings for the other comparison sites?” The answer is interesting in itself as Schmidt argues that Google’s service is not a product comparison site but a “product site” and that the study basically compares apples to oranges (“they are different animals”). Lee then homes in on the “uncanny” statistical regularity and says “I don’t know whether you call this a separate algorithm or whether you’re reverse engineered a single algorithm, but either way, you’ve cooked it!” to which Schmidt replies “I can assure you that we haven’t cooked anything.”
According to this LA Times article, Schmidt’s testimony did not satisfy the senators and there’s open talk about bias and conflict of interest. I would like to add to add three things here:
1) The debate shows a real mismatch between 20th century concepts of both bias and technology and the 21st century challenge to both of these question that comes in the form of Google. For the senator, bias is something very blatant and obvious, a malicious individual going to the server room at night, tempering with the machinery, transforming the pure technological objectivity into travesty by inserting a line of code that puts Google to third place most of the time. The problem with this view is of course that it makes a clear and strong distinction between a “biased” and an “unbiased” algorithm and clearly misses the point that every ranking procedure implies a bias. If Schmidt says “We haven’t cooked anything!”, who has written the algorithm? If it comes to an audit of Google’s code, I am certain that no “smoking gun” in the form of a primitive and obvious “manipulation” will be found. If Google wants to favor its own services, there are much more subtle and efficient ways to do so – the company does have the best SEO team one could possibly imagine after all. There is simply no need to “cook” anything if you are the one who specifies the features of the algorithm.
2) The research method applied in the mentioned study however is really quite interesting and I am curious to see how far the Senate committee will be able to take the argument. The statistical regularity shown is certainly astounding and if the hearings attain a deeper level of technological expertise, Google may be forced to detail a significant portion of its ranking procedures to show how something like this can happen. It would, of course, be extremely simple to break the pattern by introducing some random element that does not affect the average rank but adds variation. That’s also the reason why I think that Lee’s argument will ultimately fizzle.
3) The core of the problem, I would argue, is not so much the question of manipulation but the fact that by branching into more and more commercial areas, Google finds itself in a market configuration where conflicts of interest are popping up everywhere they turn. As both a search business and an actor on many of the markets that are, at least in part, ordered by the visibility layering in search results, there is a fundamental and structural problem that cannot be solved by any kind of imagined technical neutrality. Even if there is no “in house SEO” going on, the mere fact that Google search prominently links to other company services could already be seen as problematic. In a sense, Senator Lee’s argument actually creates a potentially useful “way out”: if there is no evil line of code written in the dark of night, no “smoking gun”, then everything is fine. The systematic conflict of interest persists however, and I do not believe that more subtle forms of bias towards Google services could be proven or even be seriously debated in a court of law. This level of technicality, I would argue, is no longer (fully) in reach for this kind of causal demonstration. Not so much because of the complexity of the algorithms, but rather because the “state” of the machine includes the full structure of the dataset it is working on, which means the full index in this case. To understand what Google’s algorithms actually do, looking at these algorithms without the data is no longer enough. And the data is big. Very big.
As you can see, I am quite pessimistic about the possibility to bring the kind of argumentation presented by Senator Lee to a real conclusion. If the case against Microsoft is an indicator, I would argue that this pessimism is warranted.
I do believe that we need to concentrate much more on the principal conflicts of interest rather than actual cases of abuse that may be simply too difficult to prove. The fundamental question is really how far a search company that controls such a large portion of the global market should be allowed to be active in other markets. And, really, should a single company control the search market in the first place? Limiting the very potential for abuse is, in my view, the road that legislators and regulators should take, rather than picking a fight over technological issues that they simply cannot win in the long run.
EDIT: Google has compiled its own Guide to the Hearing. Interesting.
German publisher Heise Verlag is an international curiosity. It publishes a small number of highly influential computer-related magazines that give a voice to a tech ethos that is at the same time extremely competent in the subject matter (I’ve been a steady subscriber to c’t magazin for over 15 years now, and I am still baffled sometimes just how good it is) and very much aware of the social and political implications of computing (their online magazine Telepolis testifies to that).
Data protection and privacy are long-standing concerns of the heise editors and true to a spirit of society-oriented design, they have introduced a concept as well as a technical implementation of a two-step “like” button. Such buttons, by Facebook or other companies, have of course become a major vector of user-tracking on the Web. By using an iframe, every button loads some code from Facebook’s server and sends the referring url (e.g. http://nytimes.com/articlename/blabla) as an information. The iframe being hosted on the facebook.com domain, cross-site privacy protections can be circumvented, the url information connected to an identifier cookie and, consequently, to a user account. Plugins like the Priv3 project block these mechanisms but a) users have to have a heightened level of awareness to even consider installing something like this and b) the plugin interferes with convenient functions like Google search preferences.
 Heise’s suggestion, which they already implemented on their own sites, is simple: websites can download a small bit of code that implements a two-step procedure: the “like” button is greyed out after the page first loads and there is no tracking happening. A first click on the button loads the “real” Facebook code, and the second click provides the usual functionality. The solution is very simple to implement and really a very minor inconvenience. Independently from the debate whether “like” buttons and such add any real value to the Web, this example shows that “social” features like these can be designed in a way that does not necessarily lead to pervasive user tracking.
Heise’s suggestion, which they already implemented on their own sites, is simple: websites can download a small bit of code that implements a two-step procedure: the “like” button is greyed out after the page first loads and there is no tracking happening. A first click on the button loads the “real” Facebook code, and the second click provides the usual functionality. The solution is very simple to implement and really a very minor inconvenience. Independently from the debate whether “like” buttons and such add any real value to the Web, this example shows that “social” features like these can be designed in a way that does not necessarily lead to pervasive user tracking.
The echo to this initiative has been very strong (check the Slashdot discussion here), especially in Germany, where privacy (or rather Datenschutz, a concept less centered on the individual but rather on the role of data in society) is an intensely debated issue, due to obvious historical reasons. Facebook apparently threatened to blacklist heise.de at a point, but has since then backpedaled. After all, c’t magazin prints around 600.000 issues of every number and is extremely influential in the German (and Dutch!) computer landscape. I am very curious to see how this story unfolds, because let’s be clear: Facebook’s earning potential is closely tied to its capacity to capture, enrich, and analyze user data.
This initiative – and the Heise ethos in general – underscores that a “respectable” and sober engineering culture does not exclude an explicit normative stance on social and political issues. And is shows that this stance can be translated into technical models, implemented, and shared, both as an idea and as code.
While riding my bike today, I listened to a very thought-provoking and enjoyable talk (LSE site / YouTube) given back in may at the LSE by Harvard law professor Gerald Frug, entitled “The Architecture of Governance”. The argument basically revolves around the actual “design” or “architecture” of governance/government structures and, more precisely, the complicated relationship between local and central governments. While this is not a talk about technology, there is much to learn concerning how to think about the design of (political) systems – mechanisms for organizing collective decision-making – beyond the petty moralizing and finger-pointing that seems to have taken hold of large parts of public debate today in much of the Western world. What I find quite intriguing is that Krug pays so much attention to the particularities of how seemingly consensual ideas (“power to the local”) can be implemented with rather different potential outcomes. In that sense, “parameter details” and fine-print may have a much larger impact than one might think and it’s worth-while to talk about them and not just the grand questions of “participation” vs. “representation”, and so on. Good fun!
After having sparked a series of revolutions mostly on it’s own – socioeconomics is a thing of the 20th century anyways – Twitter is looking to finally make some money off that society-changing prowess. One of the steps in that direction are the new regulations for developers, or rather, the new regulations for those who want to develop a Twitter app but are no longer welcome to do so. As this Ars Technica piece describes, apps that provide similar features as Twitter applications are no longer allowed; existing programs will be allowed to linger on, but new ones will be blocked. Ars cites a mail by developer Steve Streza on the twitter-dev mailing-list, here in full:
Twitter continues to make hostile and aggressive moves to alienate the third-party developers who helped make it the platform it is now. Today it’s third party Twitter clients. Tomorrow it’ll be URL shorteners and image/video hosts. Next it’ll be analytics and ads and who knows what else. Maybe you guys should spend some time improving the core of the service (uptime, reliability, bug fixes, etc.) rather than ingressing on the work of the thousands of developers who made Twitter an exciting place to be.
The story itself is not new. APIs are a great way for a company to experiment with new features and ideas without having to take any major risks themselves. Google led the way with Google Maps, slowly adding features to its service that had been pioneered by third party developers and deemed viable by users. Legally, there is not much to do about these practices (it they want to, companies can simply close down their web services, too) and it’s quite understandable that Twitter wants to control a value chain that promises to be quite profitable in the end. But for users and developers the reliance on private companies and closed systems is a big risk indeed. I’ve been working on a research project using Twitter data for over a year and while everything seems to be OK for the moment, what if our team suddenly gets locked out? Hundreds of hours down the drain?
When using proprietary services, you should be prepared for such things to happen but when I look at the role Twitter did play in recent events in North Africa and the Middle East – it was a mayor conduit after all – and I think about that one company’s (well, there’s Facebook, too) ability to simply close the pipes, I can’t help but feel worried. While the Internet was presented as a herald of decentralization, its global span has actually allowed for a concentration and system lock-in that is quite unique in the history of communication.
I think I’m just going to stick to email after all…